Bonjour,
Depuis 3 jours et après presque 110 jours sans arrêt ma box jeedom sur rpi pi3 plante toutes les nuits lors de la sauvegarde. L’interface web me dit :
SQLSTATE[HY000] [2002] Connection refused
puis après un rafraichissement :
SQLSTATE[HY000] [2002] No such file or directory
La box jeedom répond toujours aux ping (le plantage n’est donc pas détecté par ma prise IP qui pourrait la rebooter…) et elle est toujours accessible en SSH.
En lisant ce topic : [RESOLU] SQLSTATE[HY000] [2002] No such file or directory - #2 par jepiclo je me penche sur les fichier ib_logfile0 et ib_logfile1 dans /var/init.d/mysql, les voici :
-rw-rw---- 1 mysql mysql 33554432 Jan 15 00:26 ib_logfile0
-rw-rw---- 1 mysql mysql 33554432 Jan 15 00:26 ib_logfile1
Je les ai effacés
Au bout d’un moment, ou après plusieurs essais de restart (/etc/init.d/mysql start) ou un mdp est demandé, je perds définitivement la jeedom en ssh.
Un reboot me fait revenir 3 jours avant (je perds les historiques).
Quand j’essaye manuellement une sauvegarde voici ou cela plante :
[START BACKUP]
***************Start of Jeedom backup at 2020-01-15 04:02:26***************
Envoi l'évènement de début de sauvegarde...OK
Vérification des droits sur les fichiers...
OK
Vérification de la base de données...
et enfin j’ai plusieurs fois cette séquence dans le fichier /var/log/mysql/error.log
2020-01-15 3:09:52 1996341040 [Note] InnoDB: innodb_empty_free_list_algorithm has been changed to legacy because of small buffer pool size. In order to use backoff, increase buffer pool at least up to 20MB.
2020-01-15 3:09:52 1996341040 [Note] InnoDB: Using mutexes to ref count buffer pool pages
2020-01-15 3:09:52 1996341040 [Note] InnoDB: The InnoDB memory heap is disabled
2020-01-15 3:09:52 1996341040 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2020-01-15 3:09:52 1996341040 [Note] InnoDB: GCC builtin __atomic_thread_fence() is used for memory barrier
2020-01-15 3:09:52 1996341040 [Note] InnoDB: Compressed tables use zlib 1.2.8
2020-01-15 3:09:52 1996341040 [Note] InnoDB: Using Linux native AIO
2020-01-15 3:09:52 1996341040 [Note] InnoDB: Using generic crc32 instructions
2020-01-15 3:09:52 1996341040 [Note] InnoDB: Initializing buffer pool, size = 128.0M
2020-01-15 3:09:52 1996341040 [Note] InnoDB: Completed initialization of buffer pool
2020-01-15 3:09:52 1996341040 [Note] InnoDB: Highest supported file format is Barracuda.
2020-01-15 3:09:52 1996341040 [Note] InnoDB: Starting crash recovery from checkpoint LSN=46208640971
2020-01-15 3:09:52 1996341040 [Note] InnoDB: Restoring possible half-written data pages from the doublewrite buffer...
2020-01-15 3:09:54 1996341040 [Note] InnoDB: Starting final batch to recover 14 pages from redo log
200115 3:09:54 [ERROR] mysqld got signal 11 ;
This could be because you hit a bug. It is also possible that this binary
or one of the libraries it was linked against is corrupt, improperly built,
or misconfigured. This error can also be caused by malfunctioning hardware.
To report this bug, see https://mariadb.com/kb/en/reporting-bugs
We will try our best to scrape up some info that will hopefully help
diagnose the problem, but since we have already crashed,
something is definitely wrong and this may fail.
Server version: 10.1.37-MariaDB-0+deb9u1
key_buffer_size=16777216
read_buffer_size=131072
max_used_connections=0
max_threads=153
thread_count=0
It is possible that mysqld could use up to
key_buffer_size + (read_buffer_size + sort_buffer_size)*max_threads = 351361 K bytes of memory
Hope that's ok; if not, decrease some variables in the equation.
Thread pointer: 0x0
Attempting backtrace. You can use the following information to find out
where mysqld died. If you see no messages after this, something went
terribly wrong...
stack_bottom = 0x0 thread_stack 0x30000
The manual page at http://dev.mysql.com/doc/mysql/en/crashing.html contains
information that should help you find out what is causing the crash.
Voilà où j’en suis, je n’y connais pas grand chose, de l’aide serait grandement appréciée pour trouver une solution ![]()
Ha si, voilà ma page santé :
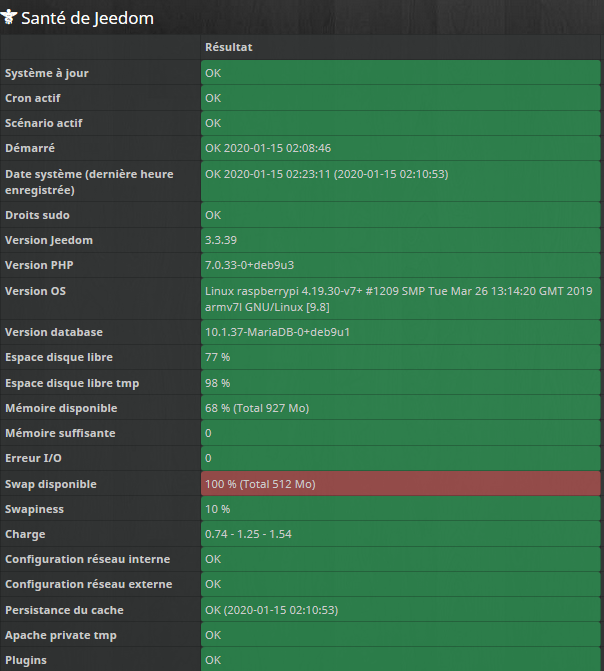
Un swap disponible à 100% … ?
j’ai tenté plusieurs fois d’augmenter le swap selon ce tuto : https://jeedom.github.io/documentation/howto/fr_FR/raspberrypi3 sans succés.
Merci beaucoup par avance de vos réponses