@fwehrle je pense en faire un article DIY est-ce que je peux te citer sur youdom pour ton excellent taf, ou je vais détailler l’article ou voir est-ce que tu veux y participer pour nous expliquer ta façon de faire ?
Encore un enorme merci à tous
1 « J'aime »
Pas de soucis pour utiliser ce que j’ai fait et merci pour la citation ![]()
Je lirais ton tuto pour voir comment améliorer mon code.
J’ai encore un peut de mal à savoir comment faire pour expliquer à chatGPT qu’il ne doit pas me dire qu’il ne peut pas fermer le garage parce qu’il est déjà ouvert… ![]()
1 « J'aime »
Hello,
Le scénario fonctionne toujours chez vous ?
J’ai suivi ton article @differentman sur Youdom.
Déjà, je n’ai pas pu intégrer les smiley de ton bloc code, cela me génère des erreurs, après nettoyage, je l’ai importé et j’ai configuré.
J’ai une erreur :
[2025-07-14 17:13:05][SCENARIO] -- Début : Scenario lance manuellement.
[2025-07-14 17:13:05][SCENARIO] - Exécution du sous-élément de type [action] : action
[2025-07-14 17:13:05][SCENARIO] Affectation de la variable jeedom_openai_api => sk-proj-ptRkFbHBxXP16XXXXXXXXXXXXXXXXXXXX (sk-proj-ptRkFbHBxXP16XXXXXXXXXXXXXXXXXXXX)
[2025-07-14 17:13:05][SCENARIO] Affectation de la variable jeedom_question => 339805 (339805)
[2025-07-14 17:13:05][SCENARIO] Affectation de la variable jeedom_sortie => 339806 (339806)
[2025-07-14 17:13:05][SCENARIO] Exécution d'un bloc élément : 2230
[2025-07-14 17:13:05][SCENARIO] - Exécution du sous-élément de type [action] : code
[2025-07-14 17:13:05][SCENARIO] Exécution d'un bloc code
[2025-07-14 17:13:05][SCENARIO] Exécution d'un bloc élément : 2231
[2025-07-14 17:13:05][SCENARIO] - Exécution du sous-élément de type [action] : code
[2025-07-14 17:13:05][SCENARIO] Exécution d'un bloc code
[2025-07-14 17:13:05][SCENARIO] Début du script Assistant Domotique avec GPT-4o.
[2025-07-14 17:13:05][SCENARIO] Test : Environnement PHP chargé avec succès.
[2025-07-14 17:13:07][SCENARIO] API Key : OK
[2025-07-14 17:13:07][SCENARIO] Capteurs Jeedom : #8369#
[2025-07-14 17:13:07][SCENARIO] Question posée : "339805"
[2025-07-14 17:13:07][SCENARIO] ID de la sortie : 339806
[2025-07-14 17:13:07][SCENARIO] Capteur récupéré : [Jardin][Station météo][Température] → 30.1
[2025-07-14 17:13:07][SCENARIO] Envoi du prompt à OpenAI...
[2025-07-14 17:13:08][SCENARIO] Erreur OpenAI : L'API n'a pas répondu.
J’ai créé ma clé ici : https://platform.openai.com/api-keys
Est-ce bon ?
Merci
Bonjour,
je vois un paramètre « timeout » = 10 dans $options, c’est peut être un peu court selon la quantité de données à traiter, a-tu essayé de l’augmenter ?
Quel est le temps de réponse moyen du scénario d’habitude ?
Hello @pifou ,
Je vais l’augmenter. Je ne sais pas te répondre, c’est la première fois que je tente ce scénario.
Pas mieux, j’ai mis un log ici :
$context = stream_context_create($options);
$scenario->setLog($context);
$response = @file_get_contents($openaiUrl, false, $context);
Il me dit : Resource id #127
Ce qui est envoyé :
[2025-07-14 17:41:12][SCENARIO] {"http":{"header":"Content-Type: application\/json\r\nAuthorization: Bearer sk-proj-ptRkFbHBxXP16XXXXXXXXXXXXXXXXXXXX ","method":"POST","content":"{\"model\":\"gpt-4o\",\"messages\":[{\"role\":\"system\",\"content\":\"Tu es un assistant domotique qui analyse les relev\u00e9s des capteurs et r\u00e9ponds aux questions de mani\u00e8re directe et pertinente.\"},{\"role\":\"user\",\"content\":\"Tu es un assistant domotique Jeedom qui analyse les relev\u00e9s des capteurs et r\u00e9pond aux questions de l'utilisateur.\\n\\n** Capteurs d\u00e9tect\u00e9s et relev\u00e9s actuels :**\\n- **[Jardin][Station m\u00e9t\u00e9o][Temp\u00e9rature]** : 29.7\u00b0C\\n\\n **Attention : Certains nombres dans la question peuvent \u00eatre des identifiants et ne sont pas des capteurs.**\\nTu dois ignorer tout chiffre qui ne correspond pas \u00e0 un relev\u00e9 de capteur.\\n\\n** Question pos\u00e9e par l'utilisateur :** \\\"339805\\\"\\n\\n**Ta mission :**\\n- Compare les relev\u00e9s des capteurs.\\n- R\u00e9ponds en **UNE seule phrase claire et directe**.\\n- Donne **l'information essentielle** sans analyser des nombres inutiles.\\n\\n**Exemple de r\u00e9ponse correcte :**\\n- \\\"Le salon est l'endroit le plus chaud avec 19.8\u00b0C.\\\"\\n- \\\"Aucun relev\u00e9 ne permet de r\u00e9pondre pr\u00e9cis\u00e9ment \u00e0 cette question.\\\"\\n\\n**R\u00e9ponds maintenant :**\"}],\"max_tokens\":200,\"temperature\":0.6}","timeout":50}}
[2025-07-14 17:41:13][SCENARIO] Erreur OpenAI : L'API n'a pas répondu.
tu a mis combien de timeout ?
C’est possible qu’il réponde plus vite en période creuse, mais la, si ça ne passe pas, met 60 (1min) ou même plus encore…
J’avais mis 50, même 100, mais le scénario n’attend pas ce délai, regarde entre l’envoi et l’erreur, il y a 1 seconde. Dois-je mettre un sleep ?
[2025-07-14 17:41:12][SCENARIO] {"http":{"header":"Content-Type: application\/json\r\nAuthorization: Bearer sk-proj-ptRkFbHBxXP16XXXXXXXXXXXXXXXXXXXX ","method":"POST","content":"{\"model\":\"gpt-4o\",\"messages\":[{\"role\":\"system\",\"content\":\"Tu es un assistant domotique qui analyse les relev\u00e9s des capteurs et r\u00e9ponds aux questions de mani\u00e8re directe et pertinente.\"},{\"role\":\"user\",\"content\":\"Tu es un assistant domotique Jeedom qui analyse les relev\u00e9s des capteurs et r\u00e9pond aux questions de l'utilisateur.\\n\\n** Capteurs d\u00e9tect\u00e9s et relev\u00e9s actuels :**\\n- **[Jardin][Station m\u00e9t\u00e9o][Temp\u00e9rature]** : 29.7\u00b0C\\n\\n **Attention : Certains nombres dans la question peuvent \u00eatre des identifiants et ne sont pas des capteurs.**\\nTu dois ignorer tout chiffre qui ne correspond pas \u00e0 un relev\u00e9 de capteur.\\n\\n** Question pos\u00e9e par l'utilisateur :** \\\"339805\\\"\\n\\n**Ta mission :**\\n- Compare les relev\u00e9s des capteurs.\\n- R\u00e9ponds en **UNE seule phrase claire et directe**.\\n- Donne **l'information essentielle** sans analyser des nombres inutiles.\\n\\n**Exemple de r\u00e9ponse correcte :**\\n- \\\"Le salon est l'endroit le plus chaud avec 19.8\u00b0C.\\\"\\n- \\\"Aucun relev\u00e9 ne permet de r\u00e9pondre pr\u00e9cis\u00e9ment \u00e0 cette question.\\\"\\n\\n**R\u00e9ponds maintenant :**\"}],\"max_tokens\":200,\"temperature\":0.6}","timeout":50}}
[2025-07-14 17:41:13][SCENARIO] Erreur OpenAI : L'API n'a pas répondu.
Je me suis aidé de ChatGPT.
[2025-07-14 20:51:24][SCENARIO] Réponse HTTP reçue : 429
[2025-07-14 20:51:24][SCENARIO] Réponse OpenAI invalide : Array
(
[error] => Array
(
[message] => You exceeded your current quota, please check your plan and billing details. For more information on this error, read the docs: https://platform.openai.com/docs/guides/error-codes/api-errors.
[type] => insufficient_quota
[param] =>
[code] => insufficient_quota
)
)
Pourtant…
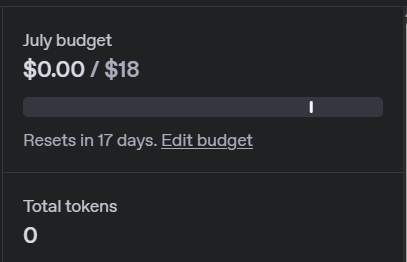
Ha ben voila, c’est clair tu a consommé tout ton budget, faut attendre 17 jours le reset,ou alors payer un petit supplément…
Je ne vois pas comment j’aurais pu consommer…
Au final, ChatGPT m’a aidé à me passer de ChatGPT ![]()
[2025-07-15 20:35:43][SCENARIO] - Exécution du sous-élément de type [action] : code
[2025-07-15 20:35:43][SCENARIO] Exécution d'un bloc code
[2025-07-15 20:35:43][SCENARIO] Début du script Assistant Domotique avec Gemini.
[2025-07-15 20:35:43][SCENARIO] Test : Environnement PHP chargé avec succès.
[2025-07-15 20:35:45][SCENARIO] API Key : OK
[2025-07-15 20:35:45][SCENARIO] Capteurs Jeedom : #8369#;#328189#
[2025-07-15 20:35:45][SCENARIO] Question posée : "Quelle température fait il dans le jardin ?"
[2025-07-15 20:35:45][SCENARIO] ID de la sortie : 339806
[2025-07-15 20:35:46][SCENARIO] Réponse HTTP reçue : 200
[2025-07-15 20:35:46][SCENARIO] Réponse envoyée à l'action : Il fait 26.7°C dans le jardin.
[2025-07-15 20:35:46][SCENARIO] Fin du script Assistant Domotique.
[2025-07-15 20:35:46][SCENARIO] Fin correcte du scénario
Souhaitez-vous que je crée un nouveau post en expliquant la méthode (même que celle décrite ci-dessus mais avec un bloc code légèrement différent) ?
Cout : Limites de débit | Gemini API | Google AI for Developers
Mathieu
2 « J'aime »
Et pourquoi ne pas juste être un peu frenchy et utiliser mistral ia.
Elle n’est pas encore au niveau pour beaucoup de choses, mais pour ce genre de chose c’est largement suffisant
Norbert
1 « J'aime »
Bonne idée !
Je teste et je vous dis ![]()
Et voilà ![]()
[2025-07-17 07:17:03][SCENARIO] Début du script Assistant Domotique avec Mistral AI.
[2025-07-17 07:17:03][SCENARIO] Test : Environnement PHP chargé avec succès.
[2025-07-17 07:17:05][SCENARIO] API Key : OK
[2025-07-17 07:17:05][SCENARIO] Capteur récupéré : [Piscine][Piscine Plugin][Température] [ID: 3836] → 29.9°C
[2025-07-17 07:17:05][SCENARIO] Capteur récupéré : [Jardin][Station météo][Température] [ID: 8369] → 21.2°C
[2025-07-17 07:17:05][SCENARIO] Capteur récupéré : [Bureau][Fenêtres][Température] [ID: 318993] → 25.1°C
[2025-07-17 07:17:05][SCENARIO] Capteur récupéré : [Grenier][Trappe][Température du module] [ID: 332473] → 30°C
[2025-07-17 07:17:05][SCENARIO] Capteur récupéré : [Cellier][Porte][Température] [ID: 319062] → 27.93°C
[2025-07-17 07:17:05][SCENARIO] Capteur récupéré : [Chambre][Fenêtres][Température] [ID: 319073] → 24.8°C
[2025-07-17 07:17:05][SCENARIO] Capteur récupéré : [Dressing][Fenêtres][Température] [ID: 319181] → 24.3°C
[2025-07-17 07:17:05][SCENARIO] Capteur récupéré : [Piscine][Capteur eau piscine][Température] [ID: 323187] → 29.93°C
[2025-07-17 07:17:05][SCENARIO] Capteur récupéré : [Salle à manger][Station météo][Température] [ID: 328189] → 23.7°C
[2025-07-17 07:17:05][SCENARIO] Capteur récupéré : [Chambre][Station météo][Température] [ID: 328200] → 24.1°C
[2025-07-17 07:17:05][SCENARIO] Capteur récupéré : [Salle de bain][Capteur][Température] [ID: 335426] → 23.9°C
[2025-07-17 07:17:05][SCENARIO] Question posée : "Quelle température fait il dans la piscine ?"
[2025-07-17 07:17:10][SCENARIO] Réponse HTTP reçue : 200
[2025-07-17 07:17:10][SCENARIO] Réponse envoyée : La température de la piscine est de 29.9°C.
[2025-07-17 07:17:10][SCENARIO] Fin du script Assistant Domotique Mistral AI.
[2025-07-17 07:17:10][SCENARIO] Exécution d'un bloc élément : 2248
[2025-07-17 07:17:10][SCENARIO] Fin correcte du scénario
[2025-07-17 07:18:53][SCENARIO] Question posée : "Peux-tu me faire un résumé des températures ?"
[2025-07-17 07:18:53][SCENARIO] Réponse HTTP reçue : 200
[2025-07-17 07:18:53][SCENARIO] Réponse envoyée : Les températures relevées sont les suivantes : 29.9°C pour la piscine, 21.2°C pour le jardin, 25.1°C pour le bureau, 30°C pour le grenier, 27.93°C pour le cellier, 24.8°C pour la chambre, 24.3°C pour le dressing, 29.93°C pour l'eau de la piscine, 23.7°C pour la salle à manger, 24.1°C pour la chambre (station météo) et 23.9°C pour la salle de bain.
Bonjour
Avez Mistral AI c’est sans limite et gratuit ?
Bonjour,
Hélas non, mais bien moins cher que OpenAI ceci dit :
Pour le modèle 4o d’OpenAI : 2.5$/m token en input et 10$ en output.
Pour le modèle « Mistral Medium 3 » de Mistral : 0.4$ en input et 2$ en output.
Je ne sais pas si on peut vraiment faire de la comparaison 1 à 1 pour ces deux modèles. Mais après même sur du OpenAI, avant de bouffer le million de tokens en ouput, faut y aller sacrément fort quand même.
Dans l’exemple précédant de Ourza, la réponse output sur la température piscine doit avoisiner les 10 tokens et dans les 150 tokens en input. Donc on est encore loin du million…
1 « J'aime »
Merci pour la réponse
et avec Gemini ?, il semble y avoir une version gratuite
Tu utiles qu’elle IA ?
Y’a effectivement une version gratuite de Gemini (modèle Gemini 2.5 pro), mais elle est limité par le nombre d’appel qu’on peut en faire :
- Maximum 5 requêtes par minute
- Maximum 100 requêtes par jour
- Maximum 250k tokens par minute
Pour de la domotique à notre niveau ça devrait suffire, sauf si tu lui demandes plus de 5 trucs dans la même minute. Sinon le modèle 2.5 Flash offre 10 requête par minute, ce qui en fait une toute les 6 secondes, ça devrait le faire.
Mais ça fera limite pour du testing, pour mettre en place un scenario ou autre, où là on a tendance à spammer régulièrement pour tester.
Et sinon la version payante du modèle 2.5 Pro est similaire à celle de Mistral : 0.3$/m token en input, et 2.5$ en output
1 « J'aime »
merci, je vais essayer, tu as un code avec l’usage de cette IA ?