Bonjour @anon53349806, en effet Lunarok a fait un super boulot avec le plugin Salat que j’utilises depuis des années. Mais là c’est pour mon père qui voudrait récupérer les heures exact de ce site (qui sont différente du plugin).
Je sais pas j’ai pas jouer avec le html / script
surement une histoire d’accés au dom mais ca manque d’exemples.
j’ai jouer avec python et la lib bs4 BeautifulSoup.
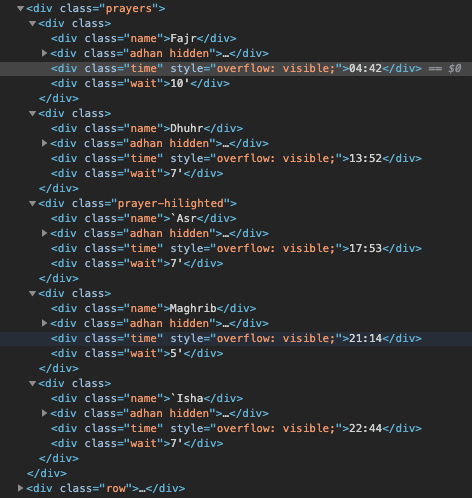
Il y a je pense une petite subtilité avec cette page.
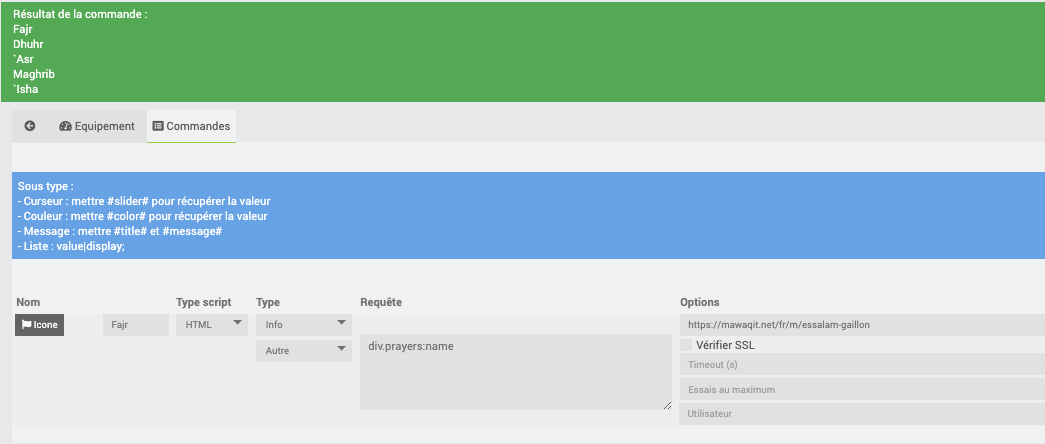
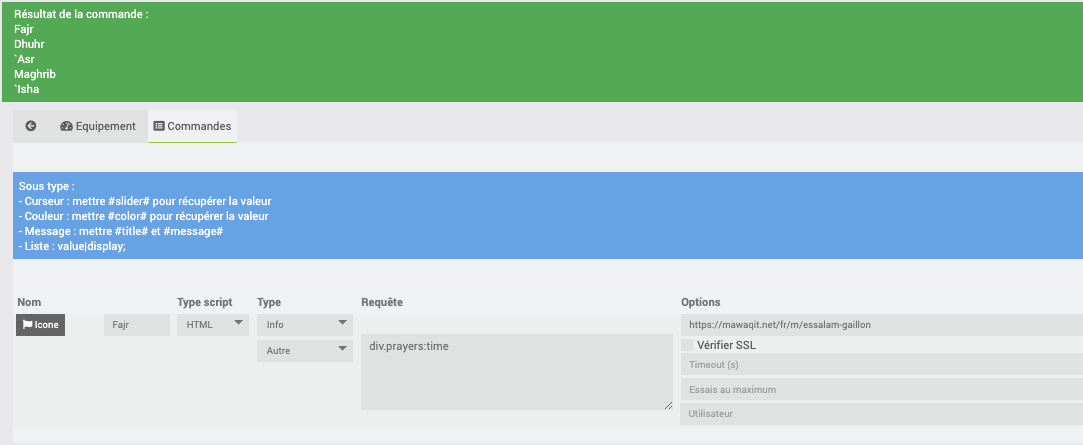
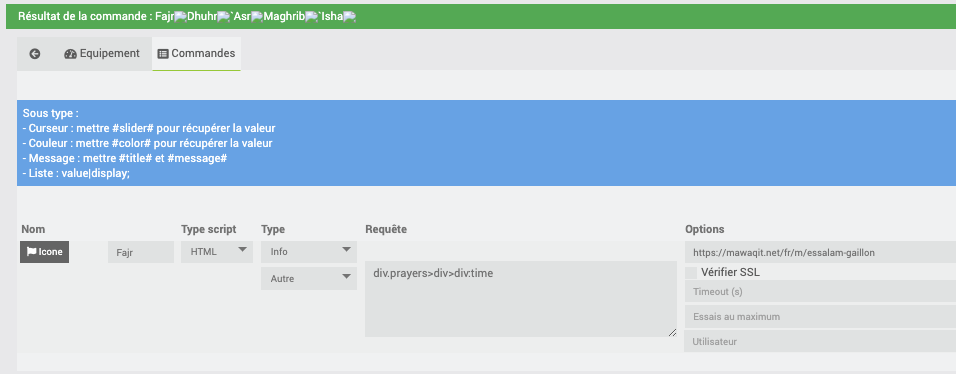
Certaines des données sont remontées par un script et n’apparaissent pas dans le DOM de la page (les balises sont vides avec Beautifulsoup)
Par contre, elles sont dispos dans une des balises script en fin de page, du coup avec un petit script python (certe pas des plus beaux, mais fonctionnel) on obtient bien la liste des heures souhaitées !
#! /usr/bin/env python3
import requests
from bs4 import BeautifulSoup
res = requests.get("https://mawaqit.net/fr/grande-mosquee-de-paris")
soupe=BeautifulSoup(res.content, "html.parser")
time_list = soupe.find_all("script")
times = time_list[2].text.split("times")[1].split("],\"iqama")[0][3:].replace("\"", "").replace(":","h").split(",")
names=["Fajr", "Dhuhr", "`Asr", "Maghrib", "`Isha"]
for i in range(0, len(names)) :
print(names[i] + " : " + times[i])