Pas sûr car sans le souligner bas j’ai une erreur et avec ça répond mais la valeur est nulle
Pas sûr car sans le souligner bas j’ai une erreur et avec ça répond mais la valeur est nulle
Bonsoir,
Merci @olive pour ce partage.
Merci également @Bben pour le code de ton scenario. Je m’en suis inspiré.
Je suis en train de faire des tests pour récupérer le suivi de colis sur le site de Mondial Relais (Leur API semblant être réservée aux pros, je tente donc le scraping. Je leur ai posé la question mais je n’ai pas eu de réponse pour le moment).
J’arrive bien à récupérer la date, l’heure et le dernier statut
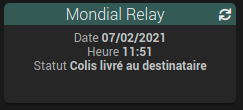
avec le code suivant :
Voici le détail du script Python :
#! /usr/bin/env python3
import requests
import urllib.parse
import posixpath
import json
import re
from sys import argv
from bs4 import BeautifulSoup
url_path = posixpath.join("suivi-de-colis/?NumeroExpedition=" + argv[1] + "&CodePostal=" + argv[2])
url = urllib.parse.urljoin("https://www.mondialrelay.fr", url_path)
res = requests.get(url)
soupe=BeautifulSoup(res.content, "html.parser")
data={}
data['date']=soupe.find(class_ = "col-xs-5").text[1:11]
data['heure']=soupe.find(class_ = "step-suivi").text.split()[0]
data['commentaire']=re.search('\n\n\n(.*)\n\n\n',str(soupe.find(class_ = "step-suivi").text.strip())).group(1)
print(json.dumps(data))
Et cela su scenario :
$scenario->setLog('---------------------------------- démarrage Test Python');
$fileURL = "/var/www/html/plugins/script/core/ressources/mondialRelay";
$numeroColis = "52846790";
$codePostal = "16200";
$command = escapeshellcmd($fileURL." ".$numeroColis." ".$codePostal);
$output = shell_exec($command);
$dataJson=json_decode($output,true);
$scenario->setLog('Date : ' . $dataJson['date']);
$scenario->setLog('Date : ' . $dataJson['heure']);
$scenario->setLog('Date : ' . $dataJson['commentaire']);
cmd::byString('#[Colis][Mondial Relay][Date]#')->event($dataJson['date']);
cmd::byString('#[Colis][Mondial Relay][Heure]#')->event($dataJson['heure']);
cmd::byString('#[Colis][Mondial Relay][Commentaire]#')->event($dataJson['commentaire']);
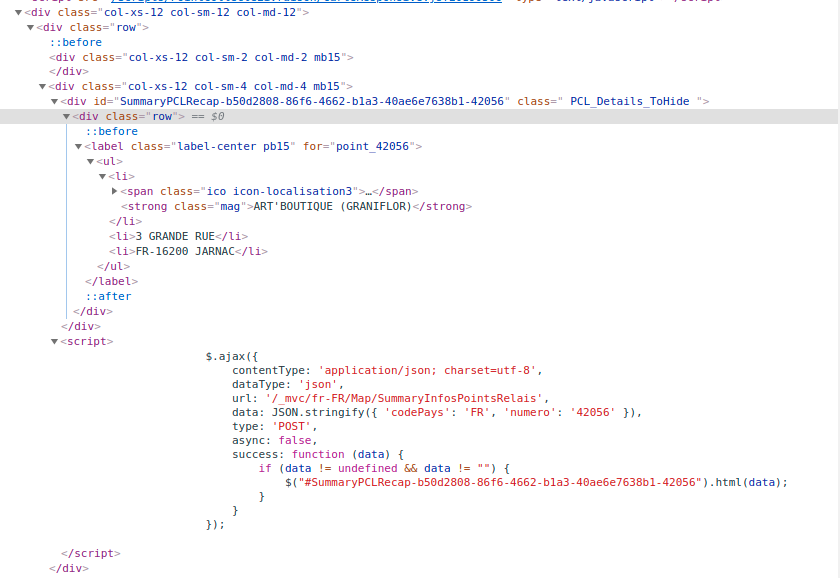
mais je n’arrive pas à récupérer le nom du relais en utlisant :
>>> soupe.find(class_ = "mag")
>>>
D’après ce que je comprend de la réponse de @ZygOm4t1k dans le post suivant :
cela pourrait venir du fait que cette partie de la page est générée dynamiquement (via du JS dans mon cas et c’était de l’Ajax dans l’exemple ci-dessus). Si on inspecte la page, on trouve bien le nom du relais (voici une URL avec un exemple de colis).
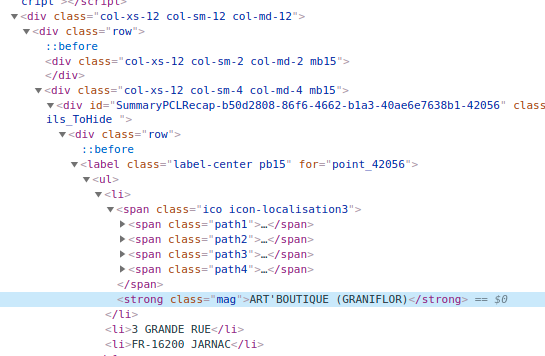
En revanche, si on regarde le code source de la page ou qu’on l’enregistre au format HTML, le nom du relais ne se trouve pas dedans.
SuiviMondialRelais.html.txt (63,1 Ko)
Si quelqu’un a une idée, je suis preneur.
Merci.
Salut
faut éplucher res
aprés
res = requests.get(url)
je ferais une écriture de res dans un fichier.txt
puis je regarderais si le nom de ton relay est dedans …
Le nom du relais n’est malheureusement pas dedans.
Les infos du relais semble se faire en Ajax
Le numéro du relais et le code Pays peuvent être récupérés dans la page
soupe.find(id="numeroTemp")["value"]
u'42056'
soupe.find(id="codePaysTemp")["value"]
u'FR'
Ensuite en faisait un post sur l’URL suivante avec les bonnes valeurs
res = requests.post("https://www.mondialrelay.fr/_mvc/fr-FR/Map/SummaryInfosPointsRelais",json={"codePays":"FR","numero":"42056"})
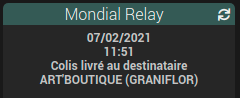
On récupère bien les infos :
"\r\n\r\n \u003cdiv class=\"row\"\u003e\r\n \u003clabel class=\"label-center pb15\" for=\"point_42056\"\u003e\r\n \u003cul\u003e\r\n \u003cli\u003e\r\n \u003cspan class=\"ico icon-localisation3\"\u003e\u003cspan class=\"path1\"\u003e\u003c/span\u003e\u003cspan class=\"path2\"\u003e\u003c/span\u003e\u003cspan class=\"path3\"\u003e\u003c/span\u003e\u003cspan class=\"path4\"\u003e\u003c/span\u003e\u003c/span\u003e\r\n \u003cstrong class=\"mag\"\u003eART\u0026#39;BOUTIQUE (GRANIFLOR)\u003c/strong\u003e\r\n \u003c/li\u003e\r\n \u003cli\u003e3 GRANDE RUE\u003c/li\u003e\r\n \u003cli\u003eFR-16200 JARNAC\u003c/li\u003e\r\n \u003c/ul\u003e\r\n\r\n \u003c/label\u003e\r\n \u003c/div\u003e\r\n"
Reste maintenant à l’extraire mais un soupe.find(class_ = "mag") ne donne rien. Je continue à creuser.
il va te falloir traiter la 2ième requette toi même.
en faite ce sont des ligne on le vois avec les \r\n
il faut le lire une a une puis nettoyer celle qui t’interesse
les \u003c et \u003e sont les < et > des balises je te laisse deviner et inventer la suite
ta balise mag est bien dedans
\u003cstrong class=\"mag\"\u003eART\u0026#39;BOUTIQUE (GRANIFLOR)\u003c/strong\u003e\r\n
se traduit par
<strong class="mag">ART'BOUTIQUE (GRANIFLOR)</strong>
peut être en supprimant tous les \r\n …
Effectivement, voici ce que ca donne.
>>> res2 = res.text.replace("\\u003c","<").replace("\\u003e",">").replace("\\r","").replace("\\n","").replace("\\","")
>>> soupe2=BeautifulSoup(res2, "html.parser")
>>> soupe2.find(class_ ="mag").text
u'ARTu0026#39;BOUTIQUE (GRANIFLOR)'
ta oublier de faire le replace u0026#39; par '
et il risque d’y en avoir d’autre si caractères spéciaux ou accentués …
![]() bravo tu est bien partit
bravo tu est bien partit
Oui, il faut que je trouve un moyen pour remplacer tout les caractères spéciaux et accentués possibles. Je vais regarder çà.
EDIT : On peut effectivement faire plus simple en utlisant le codec unicode-escape pour convertir uniquement la partie unicode, réencoder en bytes puis redécoder en utf-8
>>> res2 = res.content.decode('unicode-escape').encode('latin1').decode('utf8')
Ce qui donne :
>>> print(res2)
"
<div class="row">
<label class="label-center pb15" for="point_42056">
<ul>
<li>
<span class="ico icon-localisation3"><span class="path1"></span><span class="path2"></span><span class="path3"></span><span class="path4"></span></span>
<strong class="mag">ART'BOUTIQUE (GRANIFLOR)</strong>
</li>
<li>3 GRANDE RUE</li>
<li>FR-16200 JARNAC</li>
</ul>
</label>
</div>
"
Du coup, on peut parser directement :
>>> soup2 = BeautifulSoup(res2, "html.parser")
Et chercher la classe
>>> soup2.find(class_ ="mag").text
"ART'BOUTIQUE (GRANIFLOR)"
bonjour,
j’ai un message d’erreur qui s’affiche depuis quelques jours , c’est général ou juste chez moi ?
Erreur pour [exterieur][Ensoleillement Actuellement][Actuellement] : Erreur sur /var/www/html/plugins/script/data/soupe 0 https://www.meteoblue.com/fr/meteo/semaine/saint-remy_france_2977227 2>&1 valeur retournée : 1. Détails : Traceback (most recent call last): File « /var/www/html/plugins/script/data/soupe », line 7, in print(int(soupe.find_all(class_ = « tab_sun »)[int(argv[1])].text[62:64]), end = ‹ ›) ValueError: invalid literal for int() with base 10: ’ ’
pour moi c’est du chinois !!! si quelqu’un a une idée ca serait super .
merci par avance
J’ai pas encore regarder il est possible que la structure de la page ait changée et que la requette ne corresponde plus … ou si le site est en panne …
le site fonctionne , pas de soucis de ce coté , j’ai vérifié
Idem chez moi :
Erreur sur /var/www/html/plugins/script/data/soupe 0 Météo Lohéac - meteoblue 2>&1 valeur retournée : 1. Détails : Traceback (most recent call last): File « /var/www/html/plugins/script/data/soupe », line 7, in print(int(soupe.find_all(class_ = « tab_sun »)[int(argv[1])].text[62:64]), end = ‹ ›) ValueError: invalid literal for int() with base 10: ’ ’
Salut,
A priori ils ont rajouté un ‹ h › derrière le digit, donc ça foire le cast en integer… [Edit] je dirais plutôt que la quantité d’espace à changé, donc la selection de texte foire pour n’avoir que le nombre [/edit]
dans mon script j’ai ajouter
import re
et remplacer
subData['soleil']=int(soupe.find_all(class_ = "tab_sun")[i].text[62:64].strip())
par
subData['soleil']=int(re.findall(r'\d+',soupe.find_all(class_ = "tab_sun")[i].text[0:200].strip())[0])
…à adapter of course.
Note : d’autre champs sont arrivé hors focus dans les sous selection de texte (.text[x,y]) !
Bonjour,
Si vous avez suivi exactement la doc d’Olive (je suis pas très expert en python  ), le nouveau script est…
), le nouveau script est…
#! /usr/bin/env python3
import requests
import re
from sys import argv
from bs4 import BeautifulSoup
res = requests.get(argv[2])
soupe=BeautifulSoup(res.content, "html.parser")
print(int(re.findall(r'\d+',soupe.find_all(class_ = "tab_sun")[int(argv[1])].text[0:200].strip())[0]), end = '')
Dans mon cas, ça remarche.
Merci,
Laurent.
Merci ça marche mieux 
Bravo @LaurentP il faut juste apprendre a te servir de la balise </> pour mettre du code dans community 
tutoriel cliquez ici
Ou envoyer un message privé à @sheldon-bot démarrer tutoriel avancé pour apprendre à utiliser les menus
un badge a gagner pour la 2ième option
ps: j’ai éditer le 1er post avec ce code pour ceux qui ne sont pas adepte de lecture …
effectivement ca remarche pour moi aussi , merci beaucoup
hello,
voila des mois et des mois que je me bats avec ces scripts et rien ne fonctionnait .
Aujourd’hui ; j’ai lu la dernière phrase …
Au cas ou la librairie ne soit pas présente dans votre environnement python3.
passez en console ssh
sudo pip3 install beautifulsoup4

De suite ça fonctionne beaucoup mieux ![]()
C’est top
Je n’y arrive pas faire un truc aussi propre
Voilà j’ai une erreur le script ne ce mets plus à jour
Voici le message
[2021-05-19 03:00:33][ERROR] : Erreur pour [meteo][Durée soleil sainte maure ][j+6] : Erreur sur /var/www/html/core/php/…/…/plugins/script/data/soupe 6 https://www.meteoblue.com/fr/meteo/semaine/sainte-maure-de-touraine_france_2980403 1 2>&1 valeur retournée : 1. Détails : Traceback (most recent call last): File « /var/www/html/core/php/…/…/plugins/script/data/soupe », line 7, in print(int(soupe.find_all(class_ = « tab_sun »)[int(argv[1])].text[62:64])) ValueError: invalid literal for int() with base 10: ’ ’