C’est un peut ma faute je l’ait a la fois utiiser comme variable et comme nom de fichier …
Bonjour,
Qui fait quoi de ces informations si ce n’est pas indiscret ?
Pour l’instant j’affiche que la prod PV et l’ensoleillement du jour dans une vue sans l’exploiter plus que ça.
Je prend des décisions de consommation si les annonces de soleil pour le lendemain sont bonne.
13 messages ont été scindés en un nouveau sujet : [Partage] Widget ensoleillement
Merci merci, explications claires je cherchais ce genre de truc depuis longtemps.
Espérons que le site ne verouille pas ce genre de requete, car nous faisons 7 chargements de pages et si nous sommes de nombreux jeedomeur à faire cela c’est pas top pour eux non ?
Peut-être que l’on pourrait creer un virtuel avec les 7 infos, puis le script python ferais un load de la page meteoblue puis 7 appels internes à l’url
http://ADRESSE-IP-JEEDOM/core/api/jeeApi.php?apikey=CLE-API-JEEDOM&type=virtual&id=ID-VIRTUEL-JEEDOM&value=XXX
Je ne connais pas assez python pour me lancer encore merci en tous les cas
Rien ne t’empêche de récupérer toutes les données en une fois comme dans cet exemple !
PARTAGE prévisions nombres d'heures de soleil sur 7 jours Script Python3 - #84 par olive …
Ah oui bien sûr j’avais pas vu, merci pour l’info tout ce boulot et toute cette patience.
De rien c’est un plaisir avant tout !
1 « J'aime »
Bonjour,
J’ai lu cet intéressant article et ai déjà réussi à intégrer de nombreuses valeurs dans des virtuels.
J’ai essayé d’aller de l’avant sur le site d’un de mes fournisseurs de VMC en essayant de récupérer des valeurs par scripte, je suis coincé sur l’écriture du script car j’essaie de récupérer la valeur (ex) ci-dessous:
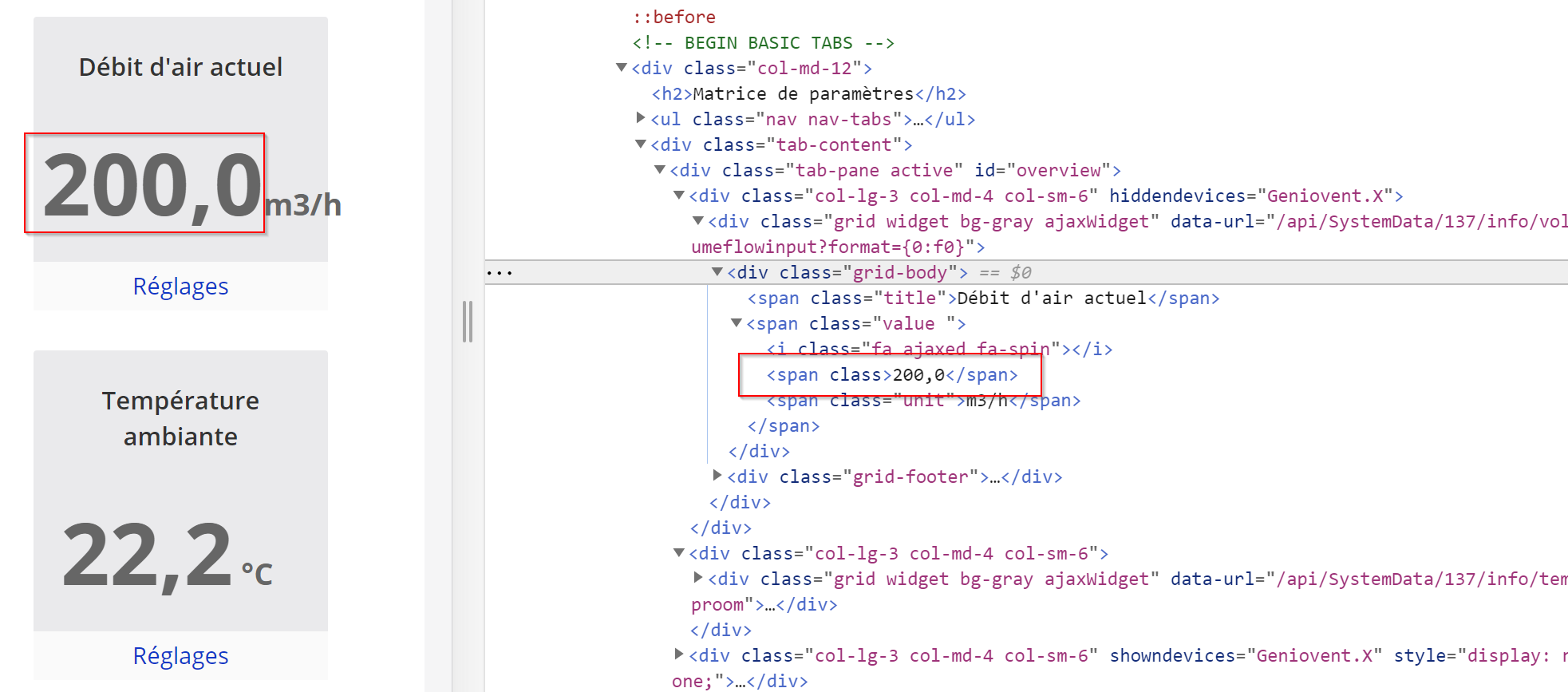
Mon script est le suivant pour une valeur unique:
#! /usr/bin/env python3
import requests
from sys import argv
from bs4 import BeautifulSoup
res = requests.get(argv[1])
soupe=BeautifulSoup(res.content, "html.parser")
print(soupe.find_all(class_="value ")[0].strip())
'200'
Mais je ne récupère pas la valeur voulue, quelqu’un a une idée ?
Merci, Joël
Il y a 3 objets dans
class_="value "
0, 1, 2
ne faut t’il pas prendre le 2ième ? (spot l’index 1 du tableau)
soupe.find_all(class_="value ")[1]
Si tu a l’adresse url de la page je veut bien tester ?
ça ne fonctionne toujours pas, j’ai l’erreur suivante
Par contre c’est un site internet ou je dois me connecter avec un username et password, serait-ce ça le problème ? J’ai indiqué mes informations de login dans le bas du script.
#! /usr/bin/env python3
import requests
from sys import argv
from bs4 import BeautifulSoup
res = requests.get(argv[1])
soupe=BeautifulSoup(res.content, "html.parser")
print(soupe.find_all(class_="value ")[1].strip())
'200'
Merci
Il te faut faire un requests avec authentification
from requests.auth import HTTPBasicAuth
requests.get('https://exemple.fr/', auth=HTTPBasicAuth('utilisateur', 'MotDePasse))
De cette manière ?
#! /usr/bin/env python3
import requests
from sys import argv
from bs4 import BeautifulSoup
from requests.auth import HTTPBasicAuth
res = requests.get('https://exemple.fr/', auth=HTTPBasicAuth('utilisateur', 'MotDePasse'))
soupe=BeautifulSoup(res.content, "html.parser")
print(soupe.find_all(class_="wind")[1].text.strip())
'200'
Oui
je vois pas pourquoi tu a toujours '200'
a la fin de tes bloc ?
Je pense que j’ai confondu avec ça, le chiffre en bout du bloc
>>> soupe.find_all(class_="wind")[0].text.split()[0]
'20'
>>>
J’ai essayé avec l’identifiant dans le script mais sans succès, j’ai toujours le message d’erreur.
Particularité, il y aussi un CAPTCHA pour se connecter au site…est-ce que ça empêche la connexion ?
La avec CAPTCHA c’est mort
a oui c’est le résultat quand on le fait en ligne
a ne pas mettre dans le code bien sur
Salut,
Je continue sur ma lancée.
Je voudrais récupérer des valeurs sur le site de mon fournisseur d’électricité et le script que j’ai créé me retourne ‹ 0 › comme valeur.
#! /usr/bin/env python3
import requests
from sys import argv
from bs4 import BeautifulSoup
from requests.auth import HTTPBasicAuth
res = requests.get('https://exemple.fr/', auth=HTTPBasicAuth('utilisateur', 'MotDePasse'))
soupe=BeautifulSoup(res.content, "html.parser")
print(soupe.find_all(class_="rouge1")[2].text.strip())
Je cherche à faire remonter les valeurs ci-dessous, une petite aide serait la bienvenue.
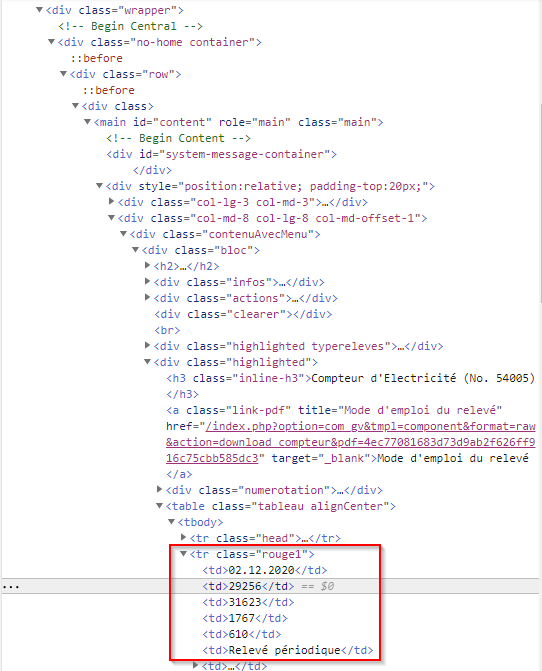
Merci
pour de-bug le mieux est que tu ouvre une fenêtre en ssh
puis tu tape python3
>>>
sur le prompt tu rentre les lignes de ton script une a une
pour la dernière tu tape juste
soupe.find_all(class_="rouge1")
comme ça tu vois ce qu’il répond
puis tu adapte
soupe.find_all(class_=« rouge1 »)[0]
soupe.find_all(class_=« rouge1 »)[1]
… etc jusqu’ à tomber sur la bonne info
aprés tu recadre la partie text fonction du résultat.
J’ai suivi scrupuleusement la méthode. J’y suis bien arrivé pour un autre site (ex. météoblue) avec un résultat, mais avec l’exemple ci-dessus je n’y arrive pas.
La valeur retournée = [ ] si je tape la la commande suivante:
>>> soup.find_all(class_ = "rouge1")
[]
Ceci dit la valeur que je recherche à isoler provient d’un tableau sur le site:

J’ai tenté de remonter une autre valeur type texte: « inline-h3 »

mais la commande me renvoie également une valeur nulle
>>> soup.find_all(class_ = "inline-h3")
[]
je sèche…
C’est peut être moi qui t’est mis sur la mauvaise piste en recopiant …
il y a pas de souligner bas …
soup.find_all(class_ = « inline-h3 »)
soup.find_all(class = "inline-h3")