Bonsoir,
Merci @olive pour ce partage.
Merci également @Bben pour le code de ton scenario. Je m’en suis inspiré.
Je suis en train de faire des tests pour récupérer le suivi de colis sur le site de Mondial Relais (Leur API semblant être réservée aux pros, je tente donc le scraping. Je leur ai posé la question mais je n’ai pas eu de réponse pour le moment).
J’arrive bien à récupérer la date, l’heure et le dernier statut
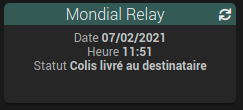
avec le code suivant :
Résumé
Voici le détail du script Python :
#! /usr/bin/env python3
import requests
import urllib.parse
import posixpath
import json
import re
from sys import argv
from bs4 import BeautifulSoup
url_path = posixpath.join("suivi-de-colis/?NumeroExpedition=" + argv[1] + "&CodePostal=" + argv[2])
url = urllib.parse.urljoin("https://www.mondialrelay.fr", url_path)
res = requests.get(url)
soupe=BeautifulSoup(res.content, "html.parser")
data={}
data['date']=soupe.find(class_ = "col-xs-5").text[1:11]
data['heure']=soupe.find(class_ = "step-suivi").text.split()[0]
data['commentaire']=re.search('\n\n\n(.*)\n\n\n',str(soupe.find(class_ = "step-suivi").text.strip())).group(1)
print(json.dumps(data))
Et cela su scenario :
$scenario->setLog('---------------------------------- démarrage Test Python');
$fileURL = "/var/www/html/plugins/script/core/ressources/mondialRelay";
$numeroColis = "52846790";
$codePostal = "16200";
$command = escapeshellcmd($fileURL." ".$numeroColis." ".$codePostal);
$output = shell_exec($command);
$dataJson=json_decode($output,true);
$scenario->setLog('Date : ' . $dataJson['date']);
$scenario->setLog('Date : ' . $dataJson['heure']);
$scenario->setLog('Date : ' . $dataJson['commentaire']);
cmd::byString('#[Colis][Mondial Relay][Date]#')->event($dataJson['date']);
cmd::byString('#[Colis][Mondial Relay][Heure]#')->event($dataJson['heure']);
cmd::byString('#[Colis][Mondial Relay][Commentaire]#')->event($dataJson['commentaire']);
mais je n’arrive pas à récupérer le nom du relais en utlisant :
>>> soupe.find(class_ = "mag")
>>>
D’après ce que je comprend de la réponse de @ZygOm4t1k dans le post suivant :
cela pourrait venir du fait que cette partie de la page est générée dynamiquement (via du JS dans mon cas et c’était de l’Ajax dans l’exemple ci-dessus). Si on inspecte la page, on trouve bien le nom du relais (voici une URL avec un exemple de colis).
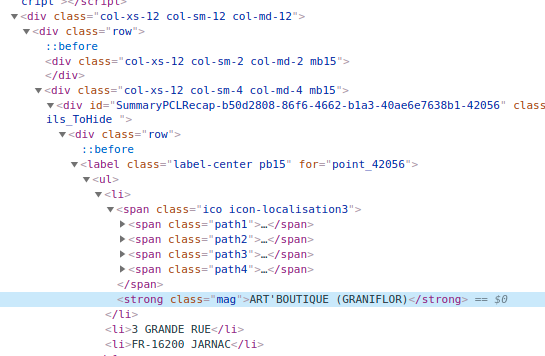
En revanche, si on regarde le code source de la page ou qu’on l’enregistre au format HTML, le nom du relais ne se trouve pas dedans.
SuiviMondialRelais.html.txt (63,1 Ko)
Si quelqu’un a une idée, je suis preneur.
Merci.