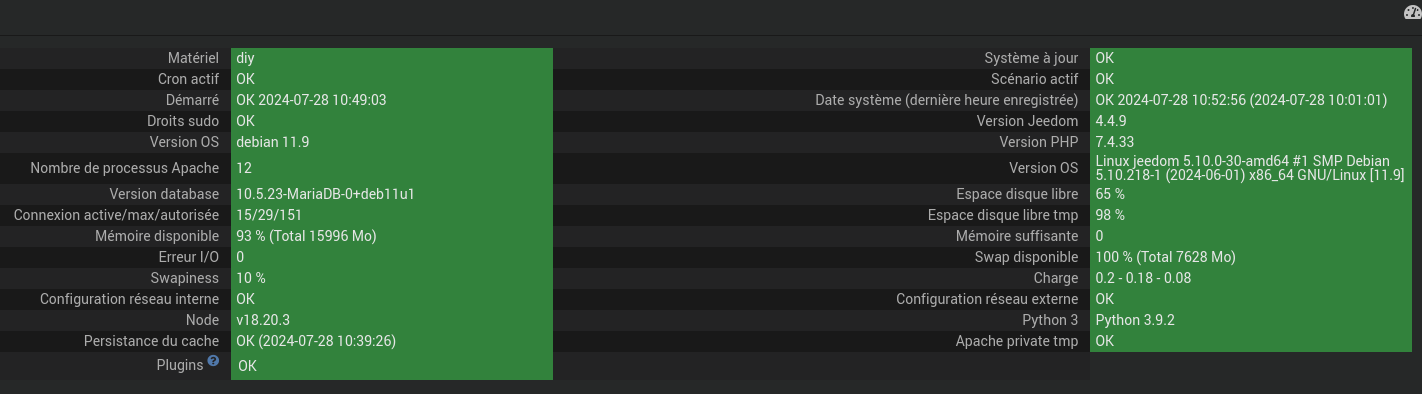
J’ai lancé un backup manuel hier soir à 23h36, et 1h20 plus tard, je n’ai toujours pas la main. La machine est extrêmement lente, les accès web n’aboutissent plus. Impossible d’accéder à la page santé ou aux logs, ça mouline à l’infini ! Pourtant on a l’impression que la tâche est finie :
Bonjour
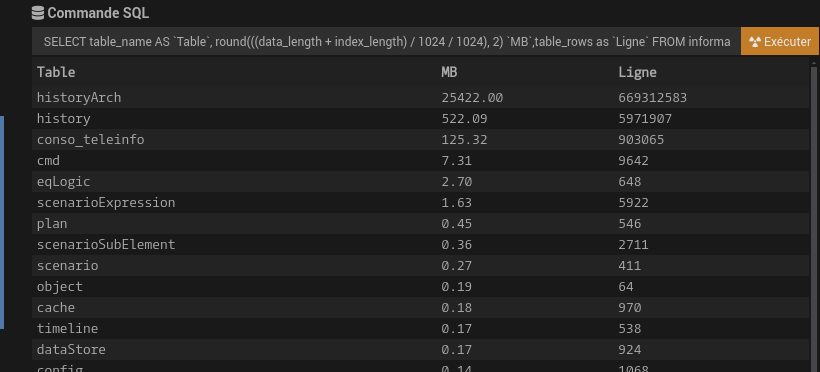
22go de base c’est un record je pense. Dans l’administration de la base de données jeedom a un bouton pour voir la taille de chaque table. Regarde déjà ça.
[EDIT]
Loïc,
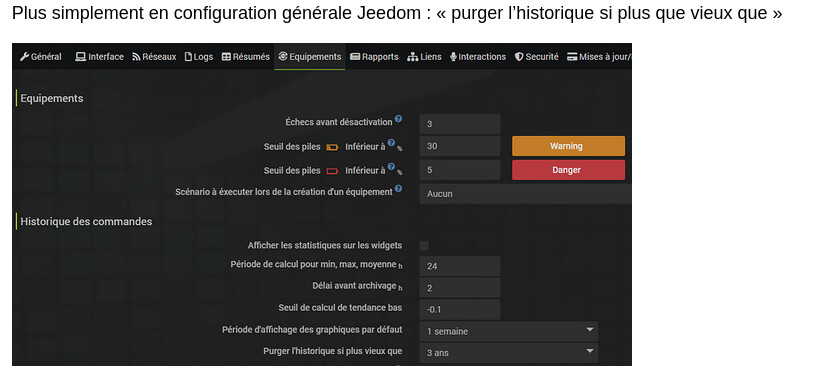
Que penses-tu d’ajouter la taille de la base à la page santé (sous « Version database ») ?
→ Cela permettrait de garder un oeil sur sa taille et de vous simplifier les diags.
Là le log est vide, mais je suppose qu’il est rempli en fin de scénario.
As-tu une idée du temps (approximatif) que cela va prendre (vu la taille de la base) ?
nb : je détaille volontairement les manips car cela peut servir à d’autres, et je posterai les résultats.
@Loic
En plus d’ajouter la taille de la base dans la page santé, pourquoi ne pas mettre le nombre de lignes de HistoryArch. Je suis certain qu’on est pas mal à mal gérer cette partie, et cela vous faciliterait l’analyse. C’est juste une idée en passant.
Bonjour
C’est pas vraiment sa place en plus faudrait mettre toute les tables. J’ai bien prévu un jour d’améliorer la page santé avec des onglets et des infos comme l’espace disque par dossier les services Linux et autre mais c’est loin d’être la priorité.
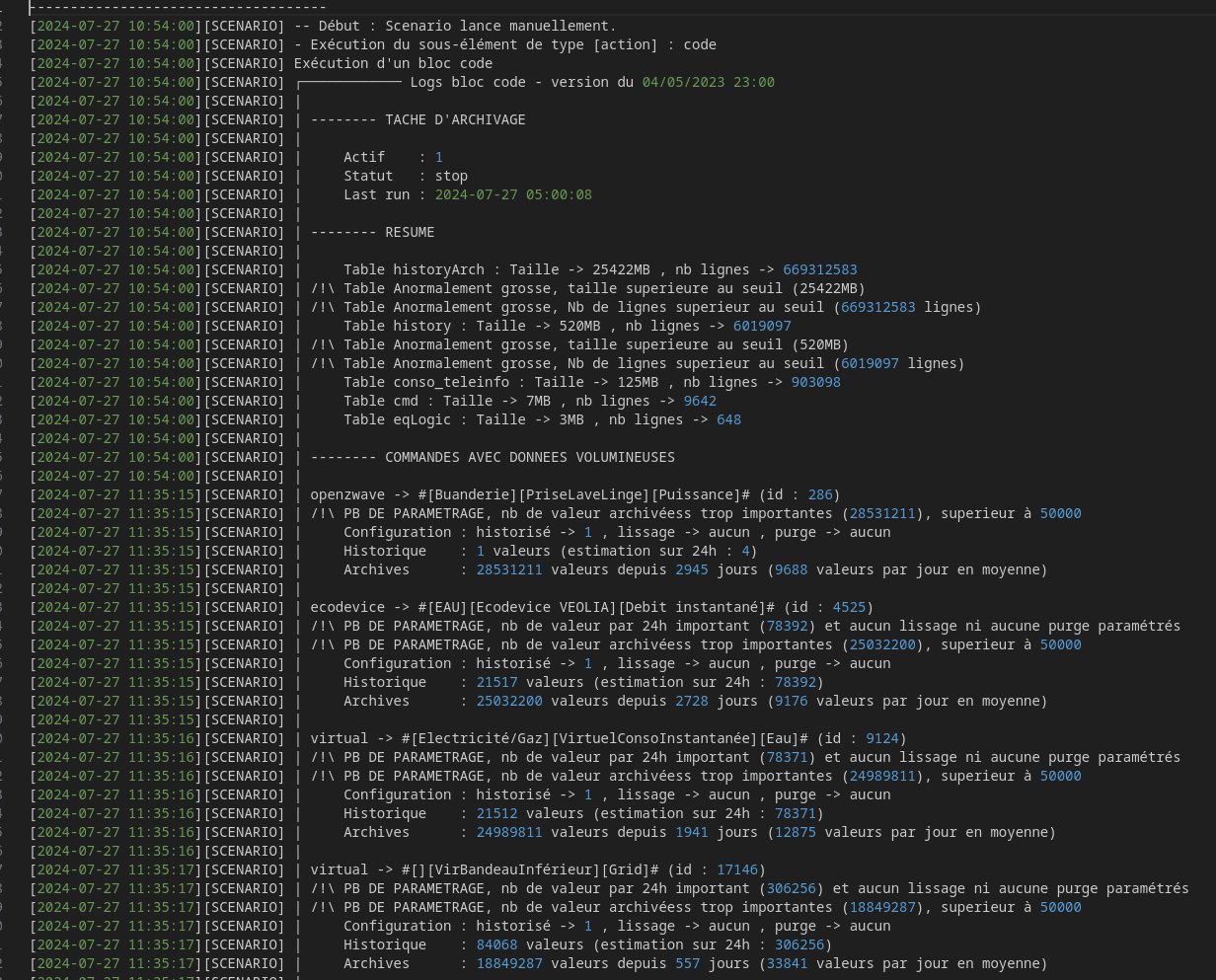
En plus ton soucis est peut être dû à un bug de la tâche d’archivage que j’ai corrigé ce matin et qui sera disponible en 4.4.10.
Faut je regarde pour la taille de la base le temps que le calcul prends (pour la table non chez toi elle a posé soucis mais chez d’autre en fonction des plugins ça peut être d’autre table).
À voir ce que je fais. La de toute façon j’ai quelques dizaine de pr en attente de validation jeedom tant que c’est pas passé je peux plus bosser sinon les merges vont être horrible (déjà que là ça risque de m’occuper pas mal d’heures)
Pour ma part, je suis assez d’accord sur le fait qu’une bd trop grosse est un signe de PB de paramétrage. Avoir la taille de la bd (juste la taille) est déjà un premier point d’alerte.
Allez plus loin dans la page santé me semble plus difficile. Après, il faut creuser
Il y a une communication Jeedom <> CerboGX (panneaux solaires) toutes les secondes (plugin mymodbus). Bizarre car cela tourne depuis des mois sans souci.
Je vais redémarrer pour voir…
Du coup peux-tu me dire comment forcer la purge ?
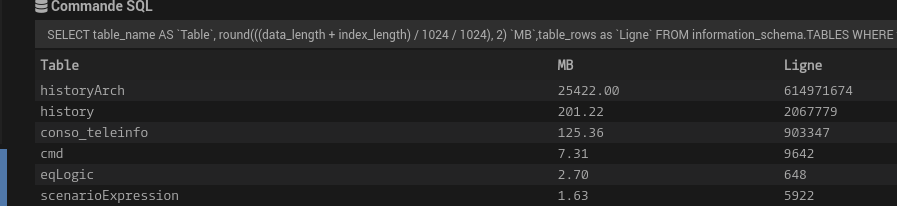
EDIT - Pour info après redémarrage c’est OK pour l’instant :
Tu peux pas forcer une purge faut juste régler la commande correctement et attendre 24h. Normalement ça marche sauf si tu as le bug de la purge qui lui sera réglé en 4.4.10. Après la tu nous a pas redonner la taille de la table donc sans ça difficile d’aider plus.
Tu a quand même un PB sur table history … 520MB, 6M de lignes. Commence déjà par régler correctement tes historiques sur les commandes, cf les commandes remontées par mon tuto.
Regarde aussi si tu n’as de pbs d’archivage (des données vielles de.plus de 1 jour dans History