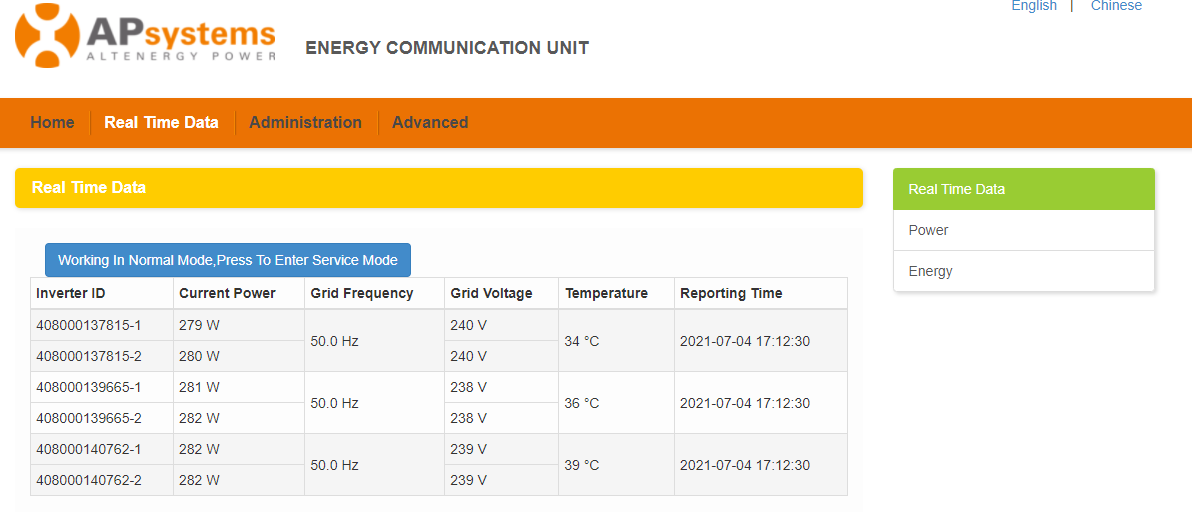
cette page est crée par mon ECU-C a laquelle j’accède par l’url : http://192.168.3.131/index.php/realtimedata
les données qui m’intéressent sont évidement date/heure, températures, puissance et numéro des micro onduleurs. ci joint le fichier de la page code page web ECU.txt (10,8 Ko)
mes jeedom sont sur des VM Proxmox, tout est a jour a la dernière version. J’ai essayé de m’inspirer de ce post mais rien a faire, ca tourne en boucle et ne s’arrête jamais : AP System API down?
une dernière précision : je ne connais aucun langage de programmation ou script… j’espère être au bon endroit pour cette question
je n’ai pas peur du cambouis, je suis capable d’en mettre partout mais je n’ai pas de compétence pour ce qui est sous jacent …
oui accès libre, en local depuis mon pc et, je pense depuis la VM concernée puisque sur le même réseau.
je vais donc partir sur la page web mais vu le temps dispo et mon temps de compréhension … le mieux est de reproduire l’exemple puis de transposer je suppose ?
je cherche, je cherche, j’essaie depuis la console mais pas moyen d’isoler ce que je veux avec Beautifulsoup et find … même find_all(‹ td ›) ne me remonte pas tout.
En regardant la page, on dirait que tous les onduleurs ne sont pas traités de la même façon entre balises et class
en fait, je pense que le plus facile serait de rechercher dans la page mes numéros d’onduleur (que je connais et que je peux mettre « en dur ») puis les puissances qui leur sont affectées. lorsque je fais soupe.find_all("408000137815"), j’obtiens je ne sais pas ce que ca signifie …
je suis partis du post ci dessous
jusque là, ca va, c’est pour affiner où je me perd dans la synthaxe …
de plus, la class active ne remonte pas tous les onduleurs, il n’y a pas cet entête sur chacun …source.txt (10,8 Ko) s
Je vois ça dans le code html (c’est u paquet de M…) c’est pas claire leur histoire qui envois les infos par 2 …
Il faut creuser comme j’ai pas le truc sous la main difficile de t’aider plus !