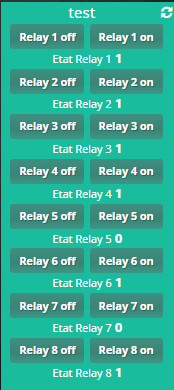
Ben on vois bien qu’il y a 2 url differentes (42 et 43)
Même si les xpath sont identique d’une page a l’autre
http://192.168.1.4/30000/42
R1 /html/body/center/center/center/p[1]/font
R2 /html/body/center/center/center/center/p[1]/font
R3 /html/body/center/center/center/center/center/p[1]/font
R4 /html/body/center/center/center/center/center/center/p[1]/font
http://192.168.1.4/30000/43
R5 /html/body/center/center/center/p[1]/font
R6 /html/body/center/center/center/center/p[1]/font
R7 /html/body/center/center/center/center/center/p[1]/font
R8 /html/body/center/center/center/center/center/center/p[1]/font
Je vois pas ou ce situe le problème ?
En python ça donne ça je vous ait mis les nom des relais en plus 
Python 3.7.3 (default, Dec 20 2019, 18:57:59)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import requests
>>> from sys import argv
>>> from bs4 import BeautifulSoup
>>> res = requests.get('http://192.168.1.4/30000/42')
>>> soupe=BeautifulSoup(res.content, "html.parser")
>>> soupe.find_all('p')[4].text.split()[0]
'Relay-01:'
>>> soupe.find_all('p')[4].text.split()[1]
'OFF'
>>> soupe.find_all('p')[6].text.split()[0]
'Relay-02:'
>>> soupe.find_all('p')[6].text.split()[1]
'OFF'
>>> soupe.find_all('p')[8].text.split()[0]
'Relay-03:'
>>> soupe.find_all('p')[8].text.split()[1]
'OFF'
>>> soupe.find_all('p')[10].text.split()[0]
'Relay-04:'
>>> soupe.find_all('p')[10].text.split()[1]
'OFF'
>>>
>>> res = requests.get('http://192.168.1.4/30000/42')
>>> soupe=BeautifulSoup(res.content, "html.parser")
>>> soupe.find_all('p')[4].text.split()[0]
'Relay-05:'
>>> soupe.find_all('p')[4].text.split()[1]
'OFF'
>>> soupe.find_all('p')[6].text.split()[0]
'Relay-06:'
>>> soupe.find_all('p')[6].text.split()[1]
'OFF'
>>> soupe.find_all('p')[8].text.split()[0]
'Relay-07:'
>>> soupe.find_all('p')[8].text.split()[1]
'OFF'
>>> soupe.find_all('p')[10].text.split()[0]
'Relay-08:'
>>> soupe.find_all('p')[10].text.split()[1]
'OFF'
>>>
Je n’ai volontairement pas mis de paramètres pour le test le script pourrait se résumer a ça
script N adresse
adresse = http://192.168.1.4/30000/42 pour les relais 1 à 4
adresse = http://192.168.1.4/30000/43 pour les relais 5 à 8
avec N= 4 pour relay 1 ou 5
avec N= 6 pour relay 2 ou 6
avec N= 8 pour relay 3 ou 7
avec N= 10 pour relay 4 ou 8
Avec le script Python3 suivant :
#! /usr/bin/env python3
import requests
from sys import argv
from bs4 import BeautifulSoup
res = requests.get(argv[2])
soupe=BeautifulSoup(res.content, "html.parser")
print(soupe.find_all('p')[int(argv[1]].text.split()[1])
on peut aussi modifier la dernière ligne si l’on veut obtenir un binaire 0 ou 1
en lieu et place de ON et OFF
0 if 'OFF'==soupe.find_all('p')[int(argv[1]].text.split()[1] else 1
Voilà 7 lignes de script c’est light quand même comparer au lourd php
ps: Au cas ou la librairie ne soit pas présente dans votre environnement python3.
passez en console ssh et tapez la commande suivante
sudo pip3 install beautifulsoup4