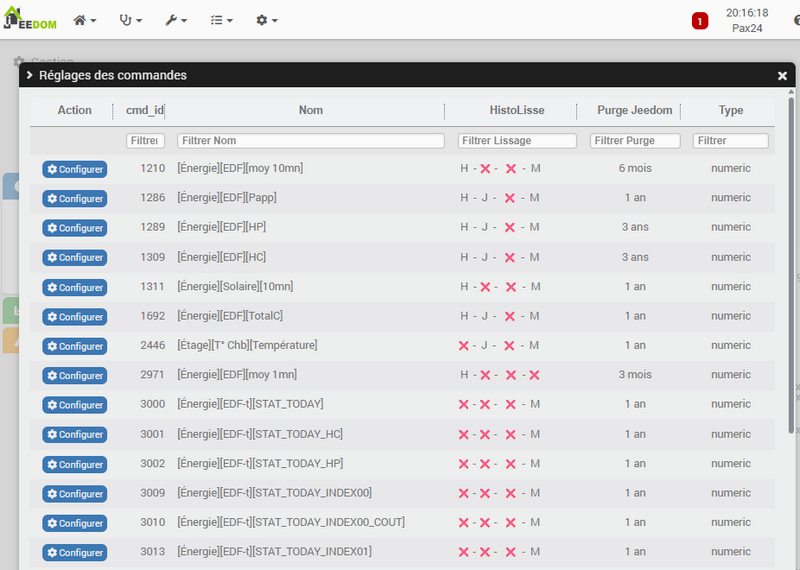
Je m’attendais à ce genre de réponse, le débat autour de l’historique dure depuis la création de Jeedom. Entre la fonctionnalité core qui fait le job dans 90% des cas, de façon simple, et une gestion avancée qui permet une approche plus fine et souple.
Beaucoup de plugins « touchent aux données » d’une manière ou d’une autre et/ou font quelque chose qui est pourtant dans les « fonctionnalités du core » en apportant un +, et/ou peuvent planter Jeedom, à minima le ralentir. Donc cet argument me semble disproportionné. Mon plugin, comme tant d’autres, enregistre des données dans l’historique : pas de quoi s’affoler.
Je n’ai rien contre une inclusion à terme dans le core d’une telle avancée, je l’ai proposé il y a plusieurs années, en vain. Mais ça prend beaucoup de place et de temps et ce n’était pas dans les priorités, et là il y a urgence.
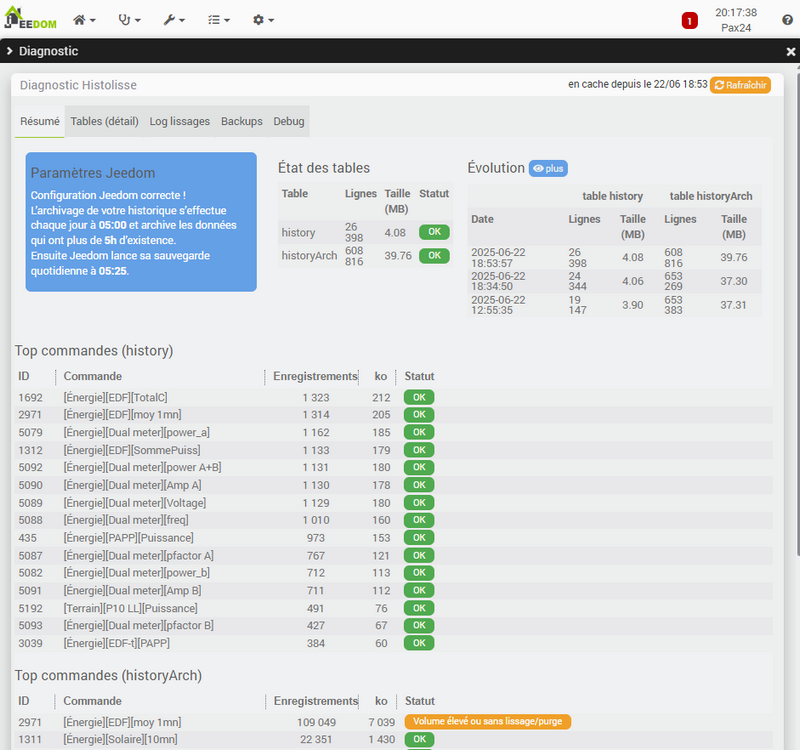
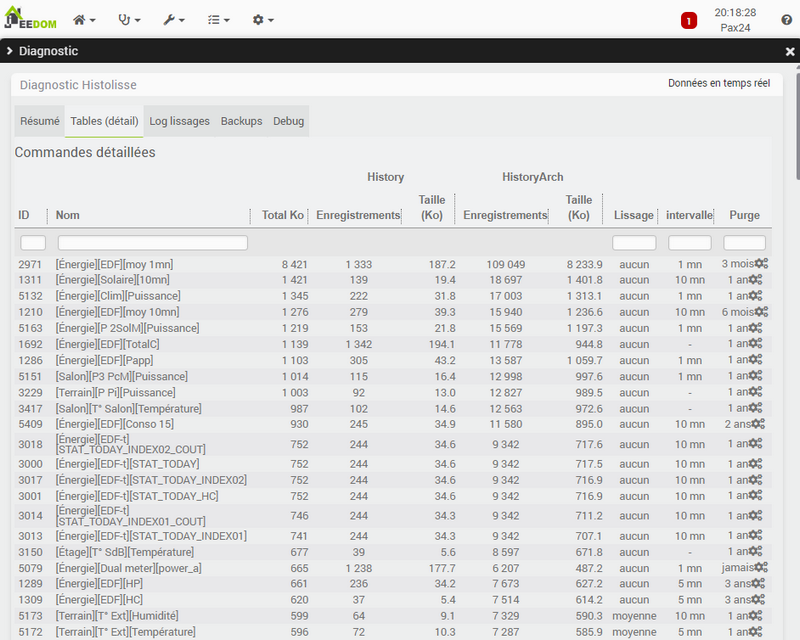
On voit bien, notamment depuis l’arrivée du MQTT, qu’un paquet de problèmes se posent avec la taille des tables d’historiques et les difficultés d’affichage des graphiques ensuite qui dégradent énormément l’UX.
A la question « j’ai des données toutes les secondes qui font agoniser ma table et ramer mon Jeedom » la seule réponse « on ne va en retenir qu’une par minute en temps réel et 1 par heure en archive » n’est pas pertinente et useless (suivi du solaire, calculs temps réel etc).
Et on assiste soit à des tables gigantesques qui rendent Jeedom pénible à utiliser, soit à des bidouillages via le plugin script qui mettent bien plus en péril l’UX et le core qu’un plugin fait pour ça et avec les garde-fous adaptés.
Ca fait plus de 300h que je bosse sur mon plugin, avec de multiples versions, J’ai finalement fait le choix de brider mon script de départ pour encadrer plus fortement les possibilités et pour que ça reste sécurisé. On est dans quelque chose qui ne fait que quelques requêtes sql basiques et dont le seul « risque », sur une mauvaise utilisation, est de « perdre » des données historisées (y’a toujours le backup cela dit).
Ce sera à voir avec les tests, mais, pour moi, ce plugin est inoffensif et offre une UX grandement améliorée tout en améliorant les performances de Jeedom de facto.
Dans mon cas c’est une taille pour historyArch divisée par 3 (par 2 pour history) sans rien perdre de l’utilité informative de mon historique, c’est un temps pour le backup Jeedom réduit de 60% et un affichage des graphs temps réel enfin fluide.
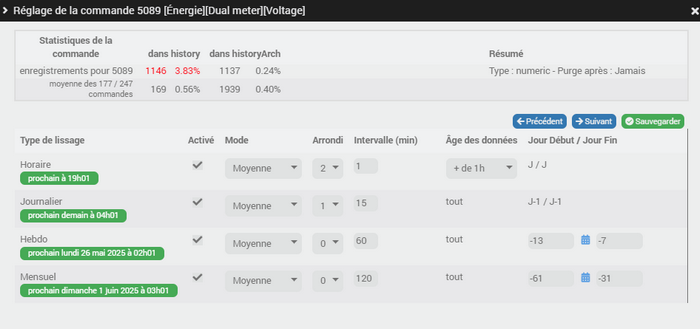
Pour donner un exemple, on peut prendre le PAPP dans la téléinfo que beaucoup ont. C’est 10 à 20 enregistrement dans history par minute, on va prendre l’hypothèse basse à 10.
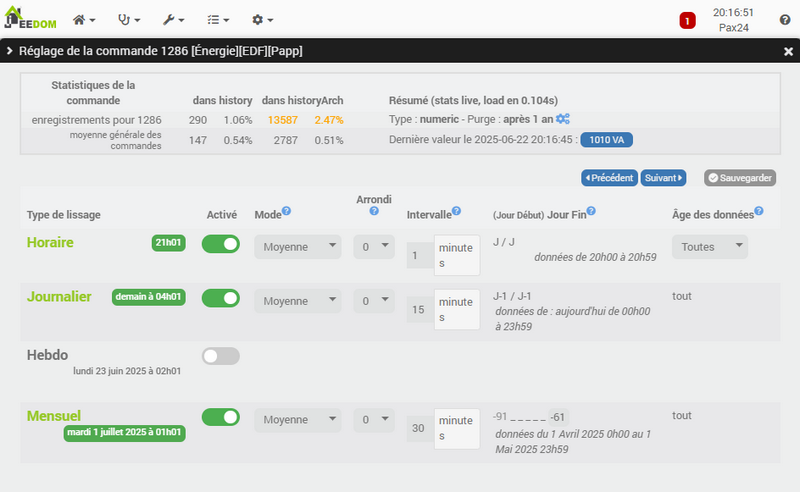
Dans mon cas, hors de question de le lisser à 1mn parce que je fais des calculs avec et que je gère du délestage, j’ai besoin de réactivité en temps réel : par contre au delà de 10mn je n’en ai plus besoin. Dans historyArch, je garde les données pour pouvoir comparer mon mois avec le mois de l’année précédente, notamment analyser par rapport au solaire et checker les ombrages etc… et aussi le comparer à ma conso Enedis qui est en 1 pour 15mn.
Avec Jeedom seul :
- Aucun lissage possible => 14 400 enregistrements dans history (qui partent dans le backup), tu ouvres un graph à 14h il a => 8400 points à afficher.
- et comme je ne veux pas de lissage par heure (mais par 15mn), et que pour la purge c’est 1 an (aucun comparatif possible, il me faudrait 1an+qq jours) ou 2 ans, on multiplie par 365*2 dans historyArch on est à => 10 millions de données…!
Avec mon plugin :
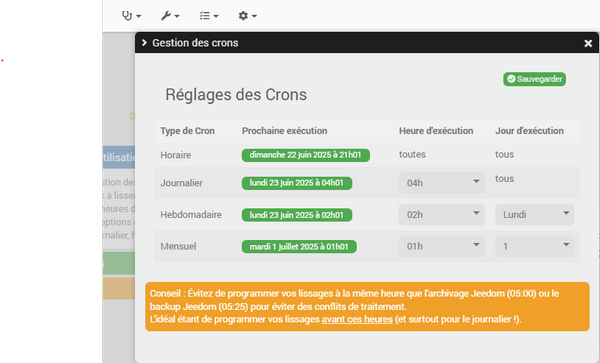
- chaque heure lissage des données si elles ont plus de 1h, sur 1mn (pour garder une info précise sur la journée) => 2 800 enregistrements dans history (x/5), tu ouvres un graph à 14h il a => 1380 points à afficher (x/6).
- lissage sur 15mn chaque nuit (avant backup) = 96 enregistrements/jour dans le backup (x/150)
- puis après 12mois+1 = lissage à 1 par jour (je n’ai pas voulu ajouter une purge au plugin) soit au total sur 2 ans, dans historyArch => 35k enregistrements (x/285).
Et bien sûr même chose pour le solaire et à moindre mesure pour d’autres trucs. Donc après on peut dire que ce n’est « pas une bonne idée » mais quand on voit la situation, des millions de données contre quelques milliers, il me semble que l’intérêt est net.