En fait, @Mips, je suis en parti d’accord avec toi.
Mais cela dépend des usages en fait. Dans le cas de Jeedom, oui, des aller retour en Bdd vs le Cache peut se comprendre. Dans le cas d’une donnée « Critique », la case « historique » fait le job en cas de crash.
Pour des applications HA, on Cloud voire Hybride (onPrem et Cloud), ou real time cela peux parfois être nécessaires. D’autant que la persistance en bdd permet la persistance des données en cas de défaillance (Rejeu des transactions, etc…). les Bdd sont assez performantes pour traiter des millions de transaction par secondes.
Par ailleurs, les applications de monitoring doivent utiliser les données des autres applications, sinon elles ne monitorent … rien. Et à un moment, si un élément change, quel qu’il soit, la métrique ne sera plus remontée de toute façon, car ne correspondant plus à rien. Comme dans l’utilisation d’application telle que Prometheus, Nagios, ou Sensu par exemple. un Reqête PromQL sera valide jusqu’au moment ou la métrique change. Il faudra alors la refaire.
Donc, je suis entièrement d’accord avec toi qu’une bdd relationnelle et une application sont un système monolithique. Qu’une application de « prod » destinées à des utilisateurs finaux ne devraient pas utiliser la bdd ou le stockage d’une autre application. Et c’est le problème des applications monolithiques. Cependant pour des usages de monitoring, c’est autre chose. Non destiné au grand public mais à des équipes IT dédiées. En cas de changement, les équipes sont là pour effectuer les corrections/ajustements nécessaires.
Par ailleurs, et c’est là justement que les nouveau modèles IT sont intéressants, l’utilisation des Microservices, Faas (les AWS Lambda par exemple), etc autres joyeusetés sont souvent amenées à utiliser des données d’autres applications pour leur usages.
En effet, prenons le cas d’une fonction Lambda. Elle est stateless et son environnement est supprimé à chaque fois donc pas d’historique, de stockage ou autre.
Imaginons une application liée à une bdd de type DynamoDb. Dans l’infrastructure, il est nécessaire d’utiliser 1 conteneur pour une tâche spécifique qui tourne continuellement.
Ce conteneur met à jour la bdd toutes les 50ms, mais les données, il ne les lis pas. il s’en fou.
Un site web (dans une instance EC2 par exemple), avec un script javascript, qui lui va lire les données de la bdd à chaque fois qu’on arrive sur la page.
Un utilisateur final utilise la page, le script se lance et appelle une API de la qui va lancer une fonction lambda. Cette fonction à besoin d’une valeur en bdd afin de faire un traitement. Le choix de la lambda est moins coûteux qu’une instance EC2 dans ce cas là. la lambda va interroger la bdd, remplie par le conteneur, et l’utiliser pour afficher une donnée « traitée »… On peux même avoir un Step Function avec plusieurs Lambda, etc… Ayant besoin de lire voire stocker ou mettre à jour une données de la Bdd.
Dans ce cas précis, ce genre d’application offre un découplage des fonctionnalités (microservice, serverless, FaaS, etc).
Mais cela fait partie d’une architecture pensée ainsi. Ce qui implique d’voir un politique de gestion du changement. Mais c’est très courant avec les nouvelles applications.
Maintenant, pour revenir à Jeedom.
C’est un cas très simple d’application monolithique. Le découpage microservice ou autre est impossible (Cron, Base de données etc…). Malgré tout, j’essaie de découpler les fonctionnalités quand cela est possible (Zwave, Blea, Mqtt, etc). Cela me permet de gérer ces fonctions dans des conteneurs comme des services.
Faire une application client fortement liée à la bdd de Jeedom est une hérésie. Je suis entièrement d’accord avec toi.
Cependant, utiliser la Bdd pour la gestion de métriques de monitoring, c’est pas pareil. C’est une utilisation technique pour récupérer des données techniques. Si une Query est cassée, l’impact n’est pas le même. La retro-compatibilité est inutile (et même une mauvaise pratique) car si le système change, le monitoring doit évoluer pour s’adapter au nouveau système. On ne veux pas rester sur l’ancien. De plus, les logiciels de monitoring utilise des times series pour la construction des courbes etc… Ce qui implique que le « pull » de Jeedom ne convient pas car on ne conserve que la dernière des données alors que l’on souhaite monitorer une période.
A ce niveau, plusieurs solutions, un exporter Prometheus, une export de chaque des données souhaitées dans une Bdd InnoDB, ou utiliser la Bdd Jeedom par exemple. C’est d’ailleurs comme cela que fonctionne l’historique de Jeedom comme j’ai pu le constaté. Pour une donnée est historisée, et pour chaque changement => Hop, une entrée en Bdd pour l’historique. Il n’y a pas le choix de toute façon.
Avec tout ça… J’espère que je suis assez clair dans ce que je veux dire. 
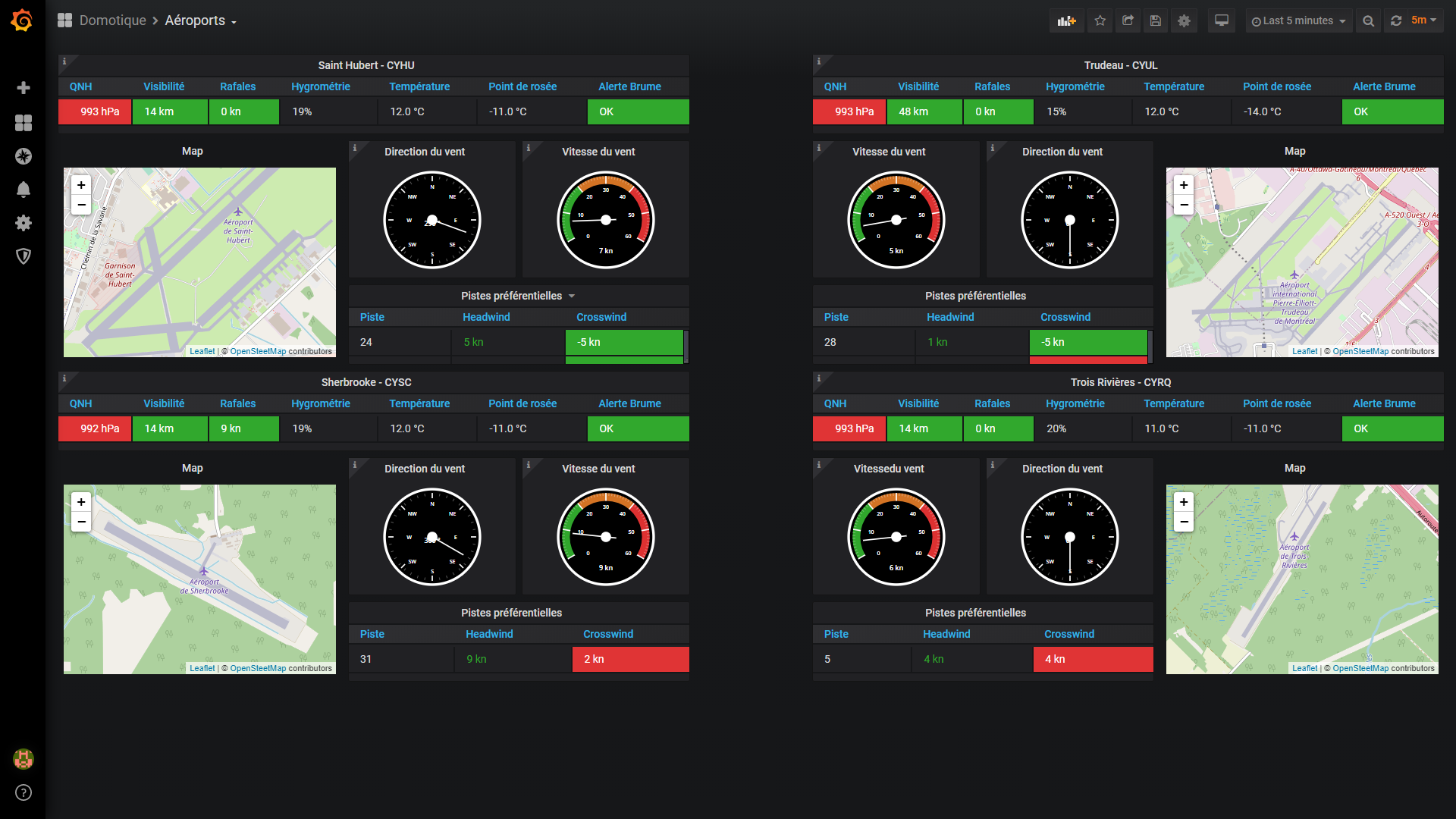
Sinon, non @axelpg, je ne me pose pas souvent à Trudeau. Je suis basé à Saint-Hubert. Mais les avions « léger » peuvent y atterrir. Il y a même une école de pilotage Mais je me sert des données pour analyser la météo avant vol.
Sinon dans mon utilisation, Jeedom est 1 application de ma stack. Cela me permet de mieux balancer les ressources matériels entre toutes mes applications (Iptv, Monitoring, Jeedom, Jenkins, Gitlab, etc…).
Si par exemple Gitlab/Jenkins et Jeedom sont à un moment sur la même ressource matérielle. Que Gitlab ou Jenkins effectue une grosse tâche CI et que les ressources manques, ça permet de faire poper Jeedom dans un autre conteneur sur un autre Odroid automatiquement. Lorsque le nouveau est UP, l’ancien conteneur s’arrête et Gitlab peux bénéficier de plus de ressource sans que Jeedom en pâtisse, le tout sans coupure de service