Je n’ai pas encore essayé de re-flasher le firmware.
Comme Jeedom fonctionne sur une machine virtuelle sur Synology Virtual Machine Manager je regarde si je trouve des informations dans les logs côté host (DSM 6.2) pour l’instant rien de flagrant.
J’ai eu le problème plusieurs fois aujourd’hui. Et ce soir il m’a semblé que la diode du RFXCOM clignotait (en orange) encore alors qu’il n’y a plus de remontée dans Jeedom sur la VM. J’ai donc supprimé le port USB sur lequel est branché le RFXCOM dans la configuration de la VM puis je l’ai ajouté à nouveau, et les sondes sont remontées dans jeedom… Je me demande si je n’ai pas un souci côté port USB dans VMM… Mais comme je fais plusieurs choses en même temps je ne suis sûr de rien… Je continue mes investigations.
Je viens de « re-flasher » en version 1043 le RFXCOM. Je verrai bien si cela change quelque chose… Dans tous les cas, cela ne change en rien la version du hardware qui est toujours 3.0 (ce qui me parait assez logique).
J’ai par contre bien constaté que le phénomène est dû à une déconnexion du RFXCOM. Sur le NAS au niveau de DSM, le dmesg faire clairement apparaître une déconnexion suivi d’un re-connexion comme par exemple :
Sun Feb 14 18:05:06 2021] usb 1-1.3: USB disconnect, device number 8
[Sun Feb 14 18:05:06 2021] usb 1-1.3: new full-speed USB device number 9 using ehci-pci
ce que je n’explique pas c’est que j’ai un décalage de 3 minutes dans les timestamp entre NAS et VM.
La déconnexion du périphérique USB côté hôte (DSM) entraine la désaffectation du périphérique FTDI (le convertisseur USB/série du RFXCOM) de la configuration de la VM. Mais la re-affectation n’étant pas automatique, la VM indique donc deux erreurs sur ftdi_sio ttyUSB0 (probablement 2 tentatives) car le périphérique n’est plus présent dans la configuration de la VM. Après cela n’explique pas pourquoi le convertisseur USB/série FTDI se déconnecte et se reconnecte dans la foulée après plusieurs heures de fonctionnement normal (entre 10 et 20 heures).
Autre phénomène très étrange, la déconnexion/re-connexion est beaucoup plus fréquente avec un hub USB alimenté (ça tient à tout casser 2 heures). J’écarte donc un problème d’alimentation insuffisante des ports USB du NAS.
J’ai bien peur que le problème soit matériel
Je vais voir si le « re-flashage » du RFXCOM change quelque chose. A+ pour d’autres constats…
Le « re-flashage » n’a rien corrigé, le problème est toujours présent. Mais quelques fois le phénomène est différent : il n’y a pas de déconnexion/reconnexion du RFXCOM visible dans le dmesg de l’hôte (DSM) mais seulement l’erreur dans le dmesg au niveau de la VM et plus de remontée dans le plugin. Dans ce cas, le redémarrage manuel du deamon du plugin corrige le souci. Mais pourquoi le heartbeat ne fonctionne-t-il pas alors, puisqu’il n’y a plus de remontée de sonde depuis plus de 5 minutes (paramétrage du heartbeat à 5 minutes) ?
Bonsoir,
Dur dur…
Regardes plus tôt les logs du RFXCOM , pour voir ce qu’il y a avant plantage.(dmesg pas trop important je pense )…
Osculte la prise du RFXCOM (femelle) oxydation, mauvais contact ?
Il n’y a rien dans le log RFXCOM (en supposant que je regarde le bon fichier log, /var/www/html/log/rfxcom ) à part le fait que les remontées de sondes s’arrêtent et qu’il y ait ensuite, mais pas systématiquement, une erreur « Error in read_rfxcom: [Errno 5] Input/output error ».
Le problème se reproduit de plus en plus souvent. Je vais quand même vérifier si c’est toujours la même « sonde » qui remonte en dernier dans les log RFXCOM (dans les fichiers que j’ai conservés).
Je pense que le problème est bien dû à la perte de la connexion USB. Les déconnexions/reconnexions du port USB vues dans le log (dmesg) du NAS, entraine la perte USB côté VM comme la ré-affectation du port USB n’est pas automatique dans la config de la VM… Je n’aurais peut-être pas le même souci avec une machine « physique » puisque je suppose que dans ce cas, en cas de déconnexiono/reconnexion le plugin redémarrerait automatiquement. Mais cela n’explique pas ces déco/reco.
Je démonterai donc le RFXCOM pour inspecter le connecteur mini-USB et aussi les soudures sur la carte, quitte à les refaire si je les trouves bizarres…
Petit retour sur mes problèmes… Je n’ai rien vu de spécial concernant le connecteur USB du RFXCOM. Le connecteur étant soudé en surface et n’étant pas un expert du fer à souder je ne me suis pas risqué à refaire les soudures.
J’ai donc essayé une autre voie de contournement. Les déconnexions/reconnexions étant maintenant récurrentes, et utilisant une VM sur Synology (avec Synology VMM), pour contourner la déconnexion/reconnexion qui entraine une « déconfiguration » du port USB côté VM, je teste actuellement la virtualisation du port USB sur IP. Pour cela j’utilise Virtualhere (https://www.virtualhere.com). Ce petit soft permet de déporter une port USB sur IP. Pour cela il faut installer un package sur le Synology et lancer un client sur la machine cible (la VM dans mon cas). Les différentes options permettent d’avoir une affectation du device RFXCOM de façon automatique côté client en utilisant la commande
./vhclientx86_64 -t "AUTO USE DEVICE,DS415PLUS.113"
puisque le RFXCOM est à « l’adresse » 1-1.3 sur mon Synology « DS415PLUS »:
En utilisant ce soft et en combinant avec le heartbeat à 2 minutes côté Jeedom, cela à l’air de fonctionner. Quand le Plugin se plante suite à une déconnexion du RFXCOM, comme la reconnexion se fait « toute seule », il est automatiquement remontée sur la VM grâce à Virtualhere et le heartbeat redémarre le plugin. Ce n’est pas parfait et un peu tordu mais cela pallie à peu près mon problème.
Seul bémol, le soft virtualhere n’est pas « free of charge », je le teste pour l’instant en version « période d’essai de 10 jours » et après je verrai si j’investis les $49 pour acquérir une licence. Ce n’est pas donné, même si la solution semble assez stable et est prête à l’emploi sur Synology…
J’ai finalement acheté la license. Cela répond dans la plupart des cas à mon problème.
Si suite à déconnexion/reconnexion du RFXCOM, le deamon du plugin se plante, alors le mécanisme de heartbeat le relance et tout fonctionne.
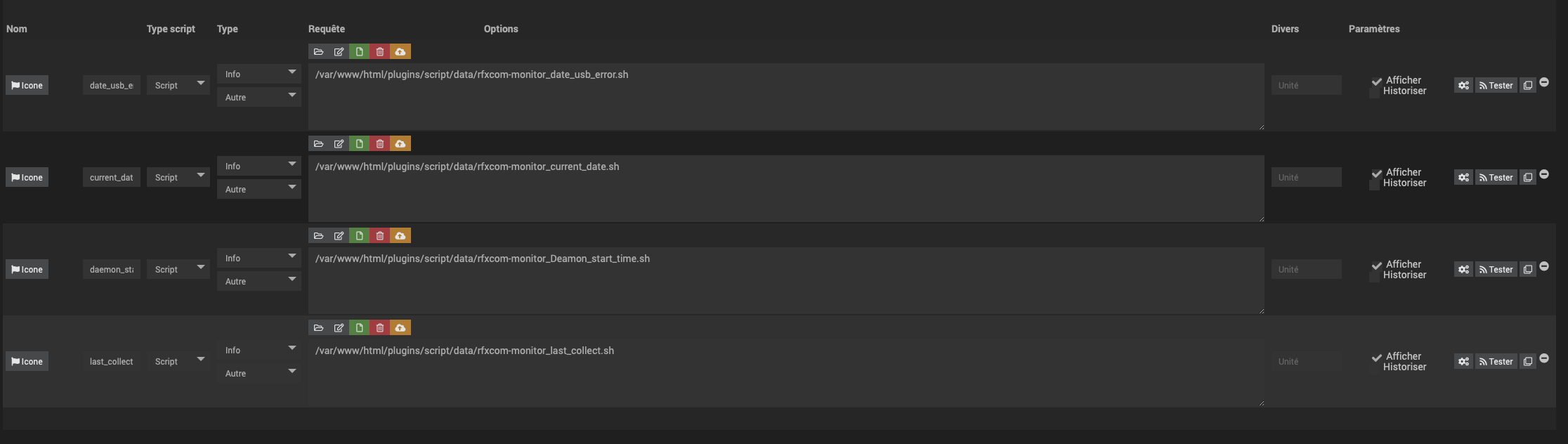
Mais dans certain cas, l’erreur USB (suite à déconnexion/reconnexion) ne fait pas planter le deamon et pourtant il n’y a plus de remontée des sondes. Et pour une raison que je ne comprends pas, le heartbeat (timeout fixé à 2 minutes) ne redémarre pas le deamon. Pour pallier ce cas, avec le plugin Script (et 3 petits scripts bash) je récupère la date du dernier démarrage du deamon, la date de dernière remontée de sonde (log du deamon RFXCOM en [DEBUG]) et la date de la dernière erreur USB et ceci toutes les minutes. J’ai créé un scénario qui s’exécute toutes les 5 minutes et effectue un test avec ces trois valeurs qui va redémarrer le deamon en utilisant le code trouvé dans ce post https://community.jeedom.com/t/scenario-pour-redemarrer-automatique-un-demon/18718.
Bonsoir, j’ai le même problème avec mon rfx sauf que je n’ai jamais eu de logs sur le plugin et rien d’anormale dans les logs du rfx. je dois redémarré jeedom en plus tout ce qui est commande en 433mhz ne marche que de façon aléatoire, après le redémarrage tout revient normale???
mais il y à environ 18 mois j’ai eu un arrêt total de tout ce qui était en 433mhz pendant plus de 18h même la clé de voiture puis c’est rentré dans l’ordre mystère pas d’explication rationnel
Peut-être des interférences dans la plage de fréquence 433MHz ?
De mon côté, j’ai un peu modifié mon test dans le scénario pour prendre un copte une condition supplémentaire :
time_diff(#[Maison][rfxcom-monitor][current_date]#,#[Maison][rfxcom-monitor][last_collect]#,m) > 5 ET (time_diff(#[Maison][rfxcom-monitor][current_date]#,#[Maison][rfxcom-monitor][date_usb_error]#,m) < time_diff(#[Maison][rfxcom-monitor][current_date]#,#[Maison][rfxcom-monitor][daemon_start_time]#,m) OU time_diff(#[Maison][rfxcom-monitor][current_date]#,#[Maison][rfxcom-monitor][last_collect]#,m) < time_diff(#[Maison][rfxcom-monitor][current_date]#,#[Maison][rfxcom-monitor][daemon_start_time]#,m))
et j’ai ajouté un contrôle dans le script de récupération de la date de dernier redémarrage du deamon :
#!/bin/bash
if [ -f "/tmp/jeedom/rfxcom/deamon.pid" ]
then
deamon_pid_file=`ls -l --time-style=full-iso /tmp/jeedom/rfxcom/deamon.pid`
echo "${deamon_pid_file:32:20}"
else
date +"%Y-%m-%d %H:%M:%S"
fi
Cela fonctionne, entre le redémarrage automatique du deamon par le heartbeating ou par le scénario, je pense que je couvre à peu près tous les cas. Cela m’évite de racheter un nouveau RFXCOM pour l’instant (de toute façon il n’est pas disponible sur le marché et peut-être ne le sera-t-il plus jamais ?).
Si je rencontre d’autres soucis, je changerai de stratégie