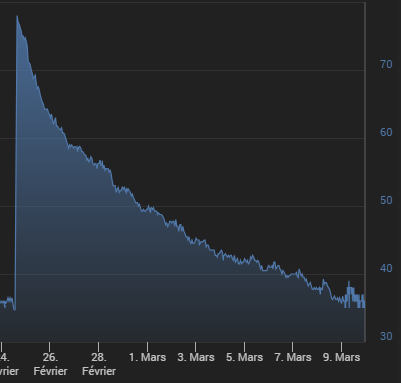
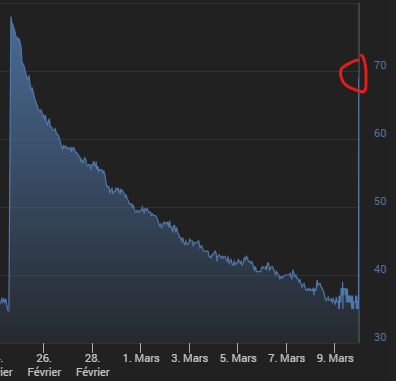
Comme ça ne semble pas clair, je vais répéter ce qui a déjà été dit :
=> version courte : Linux utilise TOUTE la mémoire disponible. C’est normal, c’est attendu et c’est logique : pourquoi acheter de la RAM pour ne pas s’en servir ? Ce serait un gaspillage d’argent et de ressources naturelles majeur. Et une faute de la part des concepteurs du système d’exploitation.
=> version longue :
Il est compréhensible que voir Linux utiliser presque toute la RAM disponible puisse être inquiétant au premier abord, surtout si on n’est pas familier avec la manière dont les systèmes d’exploitation gèrent la mémoire. Mais pas de panique, c’est en fait une bonne chose.
La RAM (mémoire vive) est une ressource précieuse et rapide, beaucoup plus rapide que le disque dur ou le SSD, les cartes SD, eMMC. Linux, comme d’autres systèmes d’exploitation modernes, essaie d’utiliser cette mémoire efficacement pour accélérer les opérations. Voici les points clés à comprendre :
- Utilisation optimisée de la RAM : Linux utilise activement la RAM disponible pour stocker des données fréquemment utilisées (comme les programmes que tu utilises) et pour la mise en cache (par exemple, les fichiers lus sur le disque). L’idée est de réduire le temps d’accès à ces données, car accéder à la RAM est beaucoup plus rapide que d’accéder au disque dur ou SSD.
- La RAM non utilisée est une RAM gaspillée : Contrairement à ce qu’on pourrait penser, avoir une grande quantité de RAM inutilisée n’est pas un signe d’efficacité. Un système efficace est un système qui utilise la RAM disponible pour améliorer les performances. Si la RAM n’est pas utilisée, elle ne sert à rien. Linux suit cette philosophie en s’assurant que la RAM est utilisée de manière productive.
- Gestion dynamique de la mémoire : Lorsque de nouvelles applications ont besoin de plus de mémoire, Linux peut libérer une partie de la mémoire utilisée pour le cache ou d’autres données moins prioritaires. Cela signifie que même si on l’impression que la RAM est pleine, il y a des mécanismes en place pour s’assurer que les applications obtiennent la mémoire dont elles ont besoin.
- Affichage des statistiques de mémoire : Les outils qui montrent l’utilisation de la mémoire sous Linux incluent souvent la mémoire utilisée pour le cache comme de la mémoire « utilisée ». Cela peut être trompeur sans le contexte approprié, car cette mémoire peut être rapidement libérée si nécessaire.
En résumé, voir Linux utiliser toute la RAM disponible n’est pas un signe de problème. C’est plutôt le signe d’un système qui travaille à maximiser ses ressources pour vous offrir la meilleure performance possible. Il est conçu pour être flexible et ajuster l’utilisation de la mémoire en fonction des besoins, assurant ainsi une expérience utilisateur fluide et réactive.
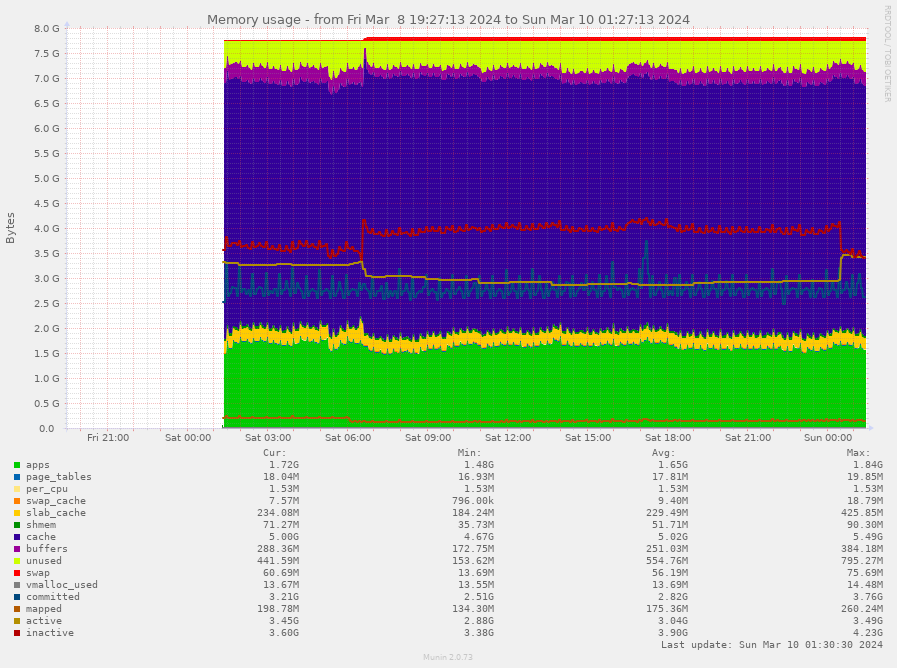
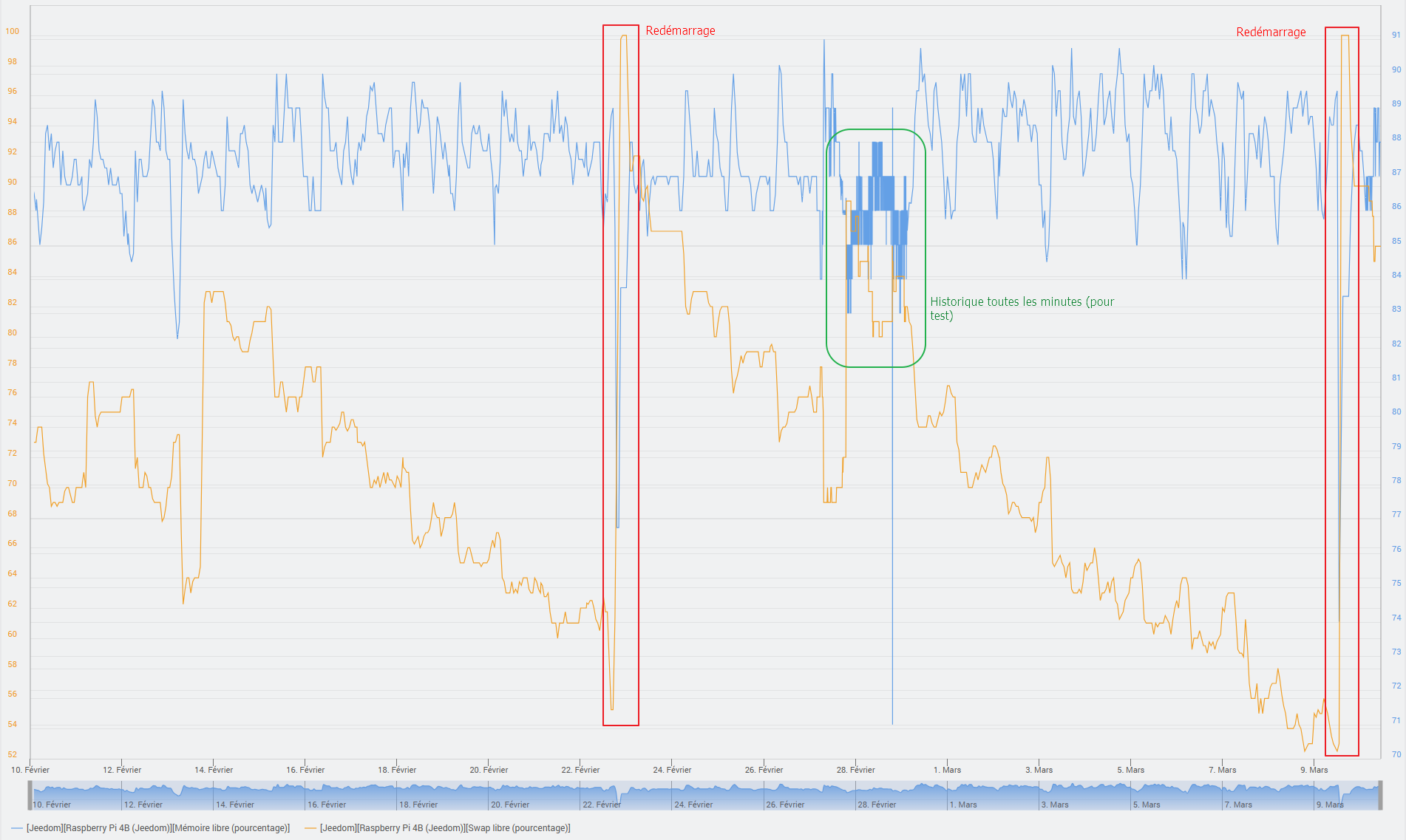
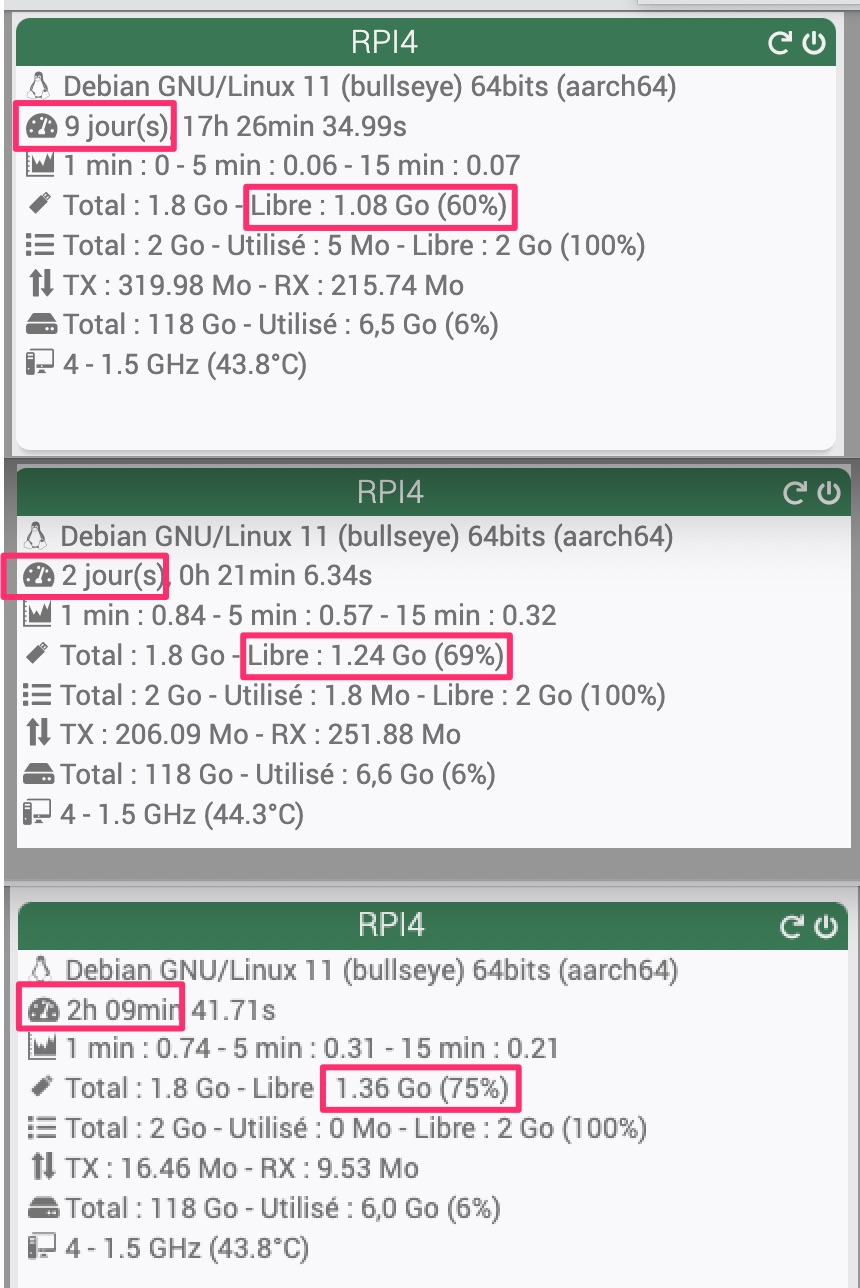
Dans la capture d’écran suivante, on peut voir l’utilisation de la mémoire d’un Jeedom doté de 8 Go de RAM (c’est beaucoup trop, même si j’ai une raison pour avoir mis en place cette configuration). Si j’affiche le même graphique que toi dans Jeedom, je verrai une courbe similaire à la tienne. On pourrait en déduire qu’il n’y a plus de RAM et que le système va planter. Pour autant, de la mémoire disponible, il y en a plein. Linux videra les caches dès que nécessaire. La mémoire réellement utilisée par Jeedom, grosso modo, c’est la zone s’affichant en vert.
Une explication détaillée de cette image donnerait quelque chose comme ceci :
Ce graphique représente l’utilisation de la mémoire sur un système Linux sur une période donnée, de vendredi soir à dimanche. Voici les éléments clés pour interpréter ce graphique :
- apps (en vert) : indique la quantité de mémoire utilisée par les applications elles-mêmes. C’est la partie de la RAM directement attribuée aux programmes en cours d’exécution.
- page_tables (en rouge) : cela montre l’espace utilisé par les tables de pages, une structure de données utilisée par le système d’exploitation pour gérer l’adresse virtuelle en adresse physique de la mémoire.
- per_cpu (en orange) : cette zone montre la mémoire allouée pour chaque processeur dans un système multiprocesseur, ce qui est habituellement une petite quantité de la mémoire totale.
- swap_cache (en bleu clair) : représente la mémoire qui a été utilisée pour des éléments qui ont été échangés (swap), mais qui sont actuellement en cache et peuvent être réutilisés sans être relus depuis le disque swap.
- slab_cache (en violet) : indique la mémoire utilisée par le kernel pour gérer des structures de données internes (slabs).
- shm (en rose) : correspond à la mémoire partagée, qui est utilisée par les processus qui accèdent à la même région de mémoire.
- buffers (en bleu foncé) : désigne la mémoire utilisée par le système d’exploitation pour stocker les buffers de disque, qui sont des blocs temporaires de données pendant les opérations d’entrée/sortie.
- unused (en jaune) : c’est la mémoire qui est actuellement non utilisée par le système.
- swap (en ligne orange en bas) : représente la quantité de mémoire virtuelle utilisée. Le swap est une extension de la mémoire RAM sur le disque dur/SSD/carte SD/EMMC. L’utilisation du swap est à éviter autant que possible. Le swap est extrèmement lent, y écrire fréquemment use les supports fragiles et quand RAM et swap sont pleins, le système plante et ne redémarre pas si un watchdog n’a pas été mis en place.
- vmalloc_used (en ligne rouge en bas) : la quantité de mémoire virtuelle allouée pour le kernel.
Les valeurs en bas du graphique montrent les statistiques courantes (Cur), minimales (Min), moyennes (Avg) et maximales (Max) pour chaque catégorie sur la période représentée.
Le graphique montre une utilisation stable de la mémoire avec une légère tendance à la hausse sur la période observée, ce qui peut être normal en fonction des applications et des services s’exécutant sur le système. Le système ne semble pas saturé, car il y a encore de la mémoire « unused » (inutilisée) et la quantité de swap utilisée est faible, ce qui indique que le système n’a pas besoin de recourir excessivement à la mémoire virtuelle, ce qui ralentirait les performances.
Il est également important de noter que le graphique inclut les mémoires tampon et le cache comme de la mémoire utilisée, alors qu’en réalité, cette mémoire peut être libérée si des applications en ont besoin, ce qui est une stratégie d’optimisation courante dans les systèmes Linux.
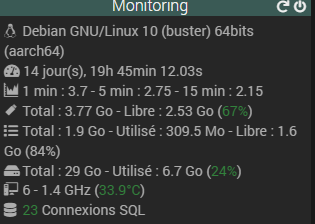
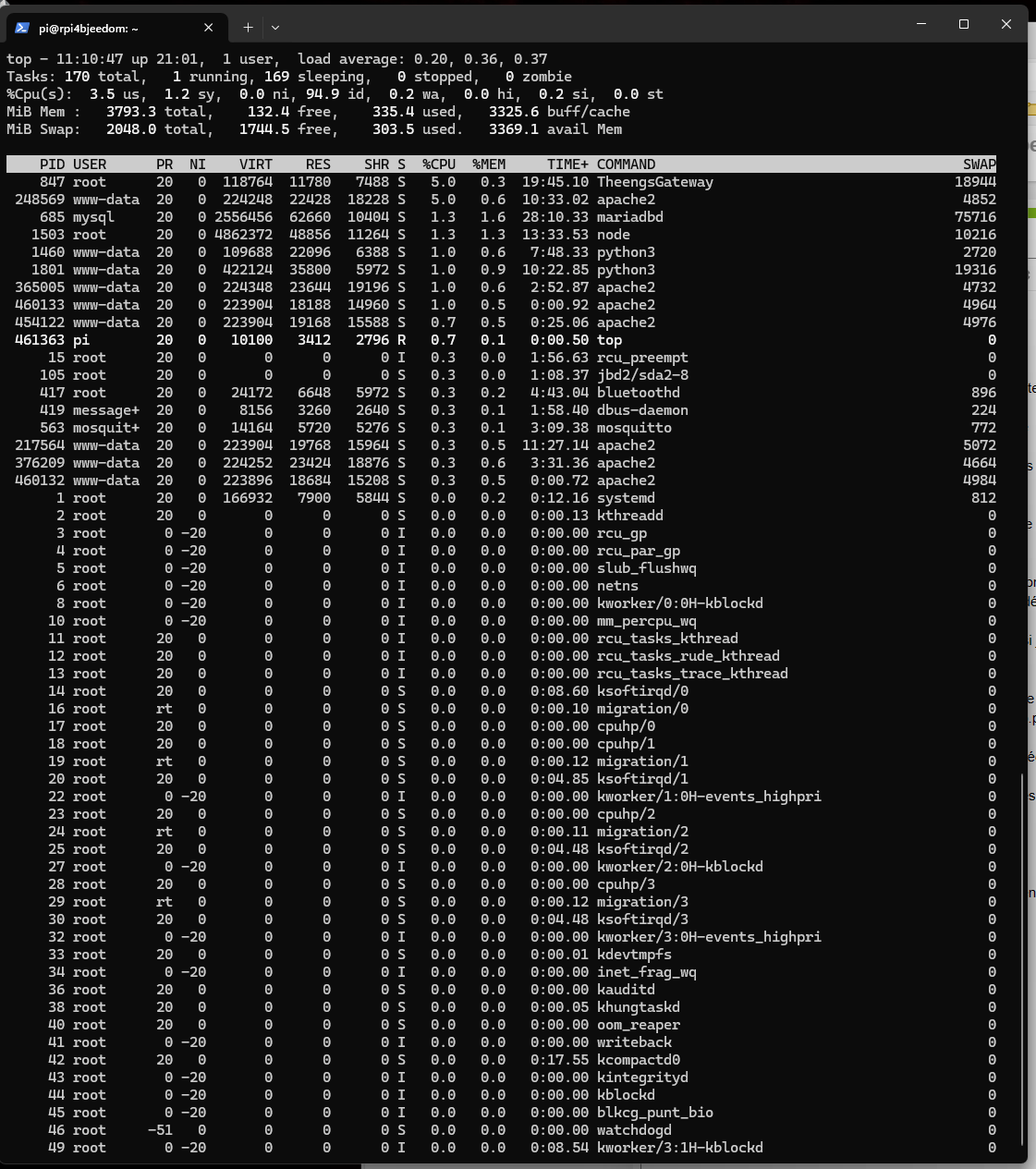
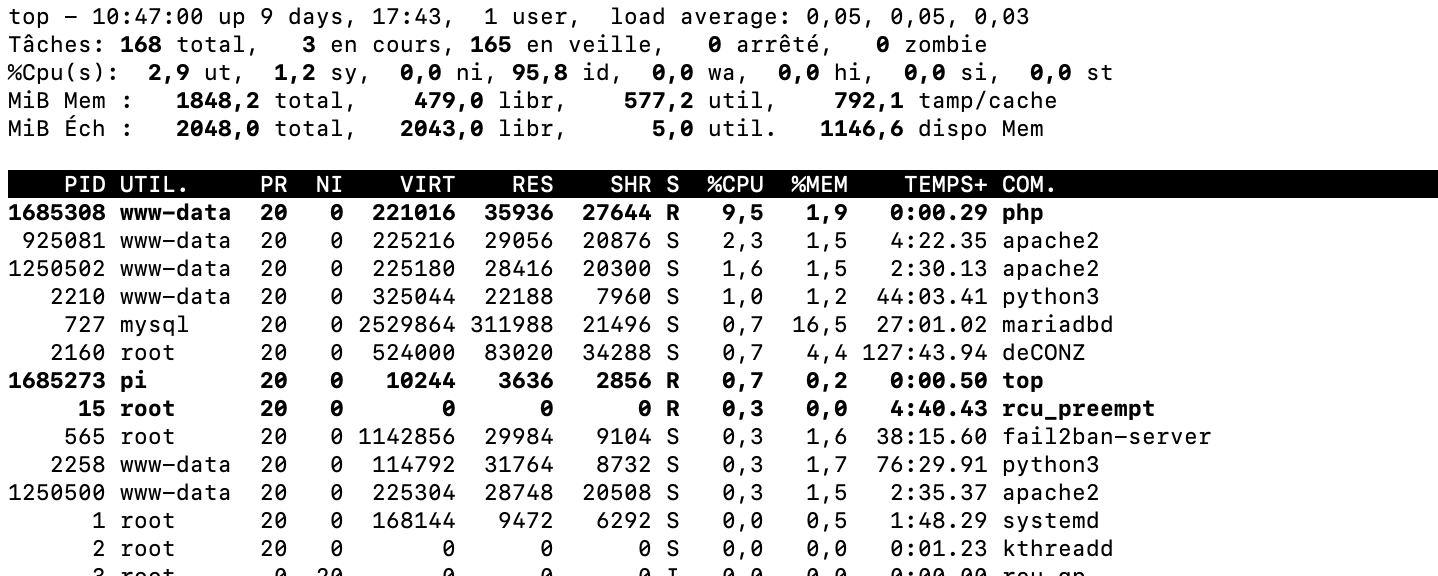
Et pour finir, une charge CPU (load average) de 3 sur une machine dotée de 6 coeurs n’est absolument pas inquiétant. Le CPU est loin d’être saturé.
Sur un système tel l’Atalas (dotée d’un CPU à 6 cœurs), un « load average » de 3 signifie que, en moyenne, la moitié des cœurs du CPU sont utilisés. Un « load average » de 1.0 signifie que l’ensemble des cœurs est chargé à 100 % (en considérant que le CPU n’a qu’un seul cœur), donc avec un CPU à 6 cœurs, un « load average » jusqu’à 6.0 signifierait que la machine est à pleine capacité (sans compter le multithreading, si disponible et applicable).
Un « load average » de 3 n’est donc pas particulièrement inquiétant, surtout si les processus sont optimisés pour le multitâche. Cela indique que le système est utilisé, mais qu’il a encore de la capacité de traitement disponible. Pour un serveur web ou une application qui gère beaucoup de petites tâches concurrentes, un « load average » légèrement supérieur au nombre de cœurs peut ne pas être inquiétant.
Bref, en conclusion cette machine ne semble absolument pas en difficulté. Quant au titre, il est erroné. On n’est pas du tout dans le cadre d’une fuite mémoire. Une fuite mémoire, c’est ça : Wikipedia - Fuite mémoire.
Tu as optimisé tes scenarios, tu obtiens le résultat que tu souhaites, le système d’exploitation ne plante pas, Linux (le noyau) ne se met pas à tuer des programmes pour protéger l’OS, ce qui rendrait Jeedom inutilisable ? Donc tout va bien. Jette un œil de temps en temps, mais tant que tout fonctionne, tout va bien