Ok merci, je m’y mets…
Ça va prendre du temps cet histoire mais je dois le faire.
Ça commence à faire beaucoups de sujets sur la perte mémoire… ![]()
Effectivement j’en vois beaucoup aussi des sujets à ce propos…
Le problème c’est de savoir comment identifier la cause et ça c’est juste très difficile !
Surveillance processus, mémoire, etc … ça ne suffit pas à déterminer où sont les limites hardware de ces box hébergeant Jeedom.
Linux ne gère-t-il finalement pas si bien que ça les resources système ?
Moi j’y comprends plus rien… alors j’arrête processus / plugins / scénarios les un après les autres mais rien n’indique un lien spécifique à ce problème de performance et je crois que c’est comme le dis Loïc que le système est peut être simplement surchargé.
Bref c’est pas gagné.
Bonjour
Regarde ta charge CPU, elle est absolument phénoménale !
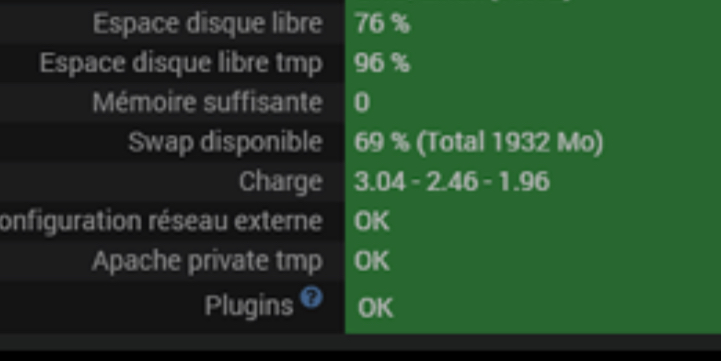
En comparaison, j’ai une Atlas avec 42 plugins, 194 scénarios, 4776 commandes et….
Je suis entre 0,28 et 0,33 sur une journée !
Sur une smart avec JeeZigbee et quelque appareils + JeeLink, je dépasse jamais les 0,15, et la moyenne sur une journée est à 0,08 …
Bref avoir un CPU a 2/3/4 c’est gigantesque !
(Sachant que 2 veut dire 200% = processeur sous l’eau / il est utilisé au double de ses capacités)
Bref 2 : ton pb n’est peut être pas la mémoire, mais un truc qui utilise le processeur bien plus qu’il ne peut !
Comme dit loic, tu desactives tout.
Tu redémarres, attends 15 minutes (le processeur 15 minutes doit rester en desous de 0,1), tu actives UN plugin, attends 15 min, etc, et tu va trouver le coupable car il y en a un….
Tu pourrais noter dans quel ordre tu actives quoi, puis comparer avec l’historique.
ta charge CPU
pas CPU, juste charge (système) => une valeur haute peut être due à la mémoire, le stockage, réseau … c’est juste un signe que des process attentent une ressource
Ha…
J’en apprends une bonne ! ![]()
(Comme quoi, c’est tout les jours)
On reste d’accord que c’est énorme
![]()
je n’aurais pas qualifié cela de « énorme »; on a déjà vu des captures d’utilisateurs ayant des valeurs de 50 à 100 => ca c’est énorme ![]()
mais c’est à surveiller, en principe un jeedom ne devrait pas être autant chargé je pense; là on est d’accord
c’est probablement un signe qu’on arrive à la limite du matériel (mais donc pas forcément du cpu)
mais combien de coeur à sa box? si 4 ou plus, on est toujours juste en dessous de la limite
Oui exacte, j’ai une charge assez concequente due a des scenarios qui s’executent toutes les minutes, exemple à 12:30:00

ensuite ça revient a une charge acceptable:
donc si je cromprends bien il peut y avoir une relation entre charge CPU et memoire due à des scenarios trop gourmants?
Je comprends bien pour le CPU mais que fait la memoire la dedans? apres l’execution d’un scénario la mémoire devrait se libérer non?
Bonjour
Non car ton scénario a besoin d’informations de la base de données et la base de données même une fois fini garde tout en mémoire au cas où tu aies encore besoin et ne libérera la ram que si l’os lui demande (en gros j’ai simplifié)
J’ai revu tous mes scenarios et j’ai mis une frequence d’execution plus espacee, par exemple si un scenario s’execute toute les minutes, j’ai mis 5 minutes, etc …
Pour l’instant j’ai tous les plugins en fonction.
La charge CPU reste acceptable mais la degringolade de la RAM continue toujours, en 2 semaines c’est incroyable comme cela chute:
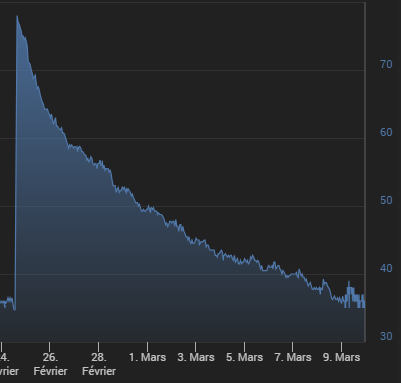
C’est pas clair cette histoire.
Je vais desactiver chaque plugin 1 a 1 et voir s’il y en a 1 qui pose soucis mais je crois deja avoir fait cela il y a quelques mois/annees et je n’ai jamais reussi a trouver ce qui provoque cette ‹ fuite de memoire ›
EDIT:
J’ai fais la mise a jour de tous les plugins & Jeedom a l’instant et la memoire est remontee a 69% !
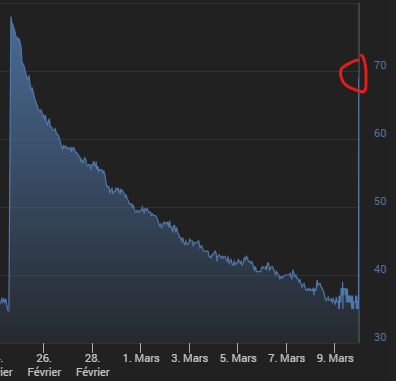
Je capte plus rien…
A suivre.
Sebastien
Bonsoir
La mémoire libre n’est pas un bon indicateur.
Comment est ta charge système ?
(C’est le seul a regarder quand on est pas un pro, il a été inventé pour cela, avoir une idée générale du système pour les quidam comme nous)
Si inférieur à 40%, tout roule.
S’il s’approche ou dépasse les 100, c’est ennuyant.
Comme ça ne semble pas clair, je vais répéter ce qui a déjà été dit :
=> version courte : Linux utilise TOUTE la mémoire disponible. C’est normal, c’est attendu et c’est logique : pourquoi acheter de la RAM pour ne pas s’en servir ? Ce serait un gaspillage d’argent et de ressources naturelles majeur. Et une faute de la part des concepteurs du système d’exploitation.
=> version longue :
Il est compréhensible que voir Linux utiliser presque toute la RAM disponible puisse être inquiétant au premier abord, surtout si on n’est pas familier avec la manière dont les systèmes d’exploitation gèrent la mémoire. Mais pas de panique, c’est en fait une bonne chose.
La RAM (mémoire vive) est une ressource précieuse et rapide, beaucoup plus rapide que le disque dur ou le SSD, les cartes SD, eMMC. Linux, comme d’autres systèmes d’exploitation modernes, essaie d’utiliser cette mémoire efficacement pour accélérer les opérations. Voici les points clés à comprendre :
- Utilisation optimisée de la RAM : Linux utilise activement la RAM disponible pour stocker des données fréquemment utilisées (comme les programmes que tu utilises) et pour la mise en cache (par exemple, les fichiers lus sur le disque). L’idée est de réduire le temps d’accès à ces données, car accéder à la RAM est beaucoup plus rapide que d’accéder au disque dur ou SSD.
- La RAM non utilisée est une RAM gaspillée : Contrairement à ce qu’on pourrait penser, avoir une grande quantité de RAM inutilisée n’est pas un signe d’efficacité. Un système efficace est un système qui utilise la RAM disponible pour améliorer les performances. Si la RAM n’est pas utilisée, elle ne sert à rien. Linux suit cette philosophie en s’assurant que la RAM est utilisée de manière productive.
- Gestion dynamique de la mémoire : Lorsque de nouvelles applications ont besoin de plus de mémoire, Linux peut libérer une partie de la mémoire utilisée pour le cache ou d’autres données moins prioritaires. Cela signifie que même si on l’impression que la RAM est pleine, il y a des mécanismes en place pour s’assurer que les applications obtiennent la mémoire dont elles ont besoin.
- Affichage des statistiques de mémoire : Les outils qui montrent l’utilisation de la mémoire sous Linux incluent souvent la mémoire utilisée pour le cache comme de la mémoire « utilisée ». Cela peut être trompeur sans le contexte approprié, car cette mémoire peut être rapidement libérée si nécessaire.
En résumé, voir Linux utiliser toute la RAM disponible n’est pas un signe de problème. C’est plutôt le signe d’un système qui travaille à maximiser ses ressources pour vous offrir la meilleure performance possible. Il est conçu pour être flexible et ajuster l’utilisation de la mémoire en fonction des besoins, assurant ainsi une expérience utilisateur fluide et réactive.
Dans la capture d’écran suivante, on peut voir l’utilisation de la mémoire d’un Jeedom doté de 8 Go de RAM (c’est beaucoup trop, même si j’ai une raison pour avoir mis en place cette configuration). Si j’affiche le même graphique que toi dans Jeedom, je verrai une courbe similaire à la tienne. On pourrait en déduire qu’il n’y a plus de RAM et que le système va planter. Pour autant, de la mémoire disponible, il y en a plein. Linux videra les caches dès que nécessaire. La mémoire réellement utilisée par Jeedom, grosso modo, c’est la zone s’affichant en vert.
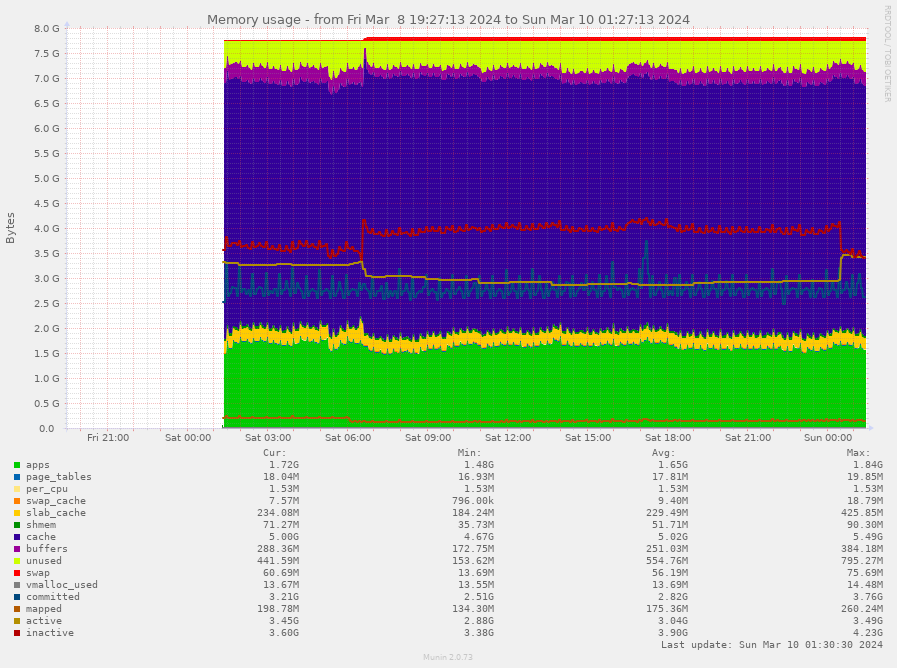
Une explication détaillée de cette image donnerait quelque chose comme ceci :
Ce graphique représente l’utilisation de la mémoire sur un système Linux sur une période donnée, de vendredi soir à dimanche. Voici les éléments clés pour interpréter ce graphique :
- apps (en vert) : indique la quantité de mémoire utilisée par les applications elles-mêmes. C’est la partie de la RAM directement attribuée aux programmes en cours d’exécution.
- page_tables (en rouge) : cela montre l’espace utilisé par les tables de pages, une structure de données utilisée par le système d’exploitation pour gérer l’adresse virtuelle en adresse physique de la mémoire.
- per_cpu (en orange) : cette zone montre la mémoire allouée pour chaque processeur dans un système multiprocesseur, ce qui est habituellement une petite quantité de la mémoire totale.
- swap_cache (en bleu clair) : représente la mémoire qui a été utilisée pour des éléments qui ont été échangés (swap), mais qui sont actuellement en cache et peuvent être réutilisés sans être relus depuis le disque swap.
- slab_cache (en violet) : indique la mémoire utilisée par le kernel pour gérer des structures de données internes (slabs).
- shm (en rose) : correspond à la mémoire partagée, qui est utilisée par les processus qui accèdent à la même région de mémoire.
- buffers (en bleu foncé) : désigne la mémoire utilisée par le système d’exploitation pour stocker les buffers de disque, qui sont des blocs temporaires de données pendant les opérations d’entrée/sortie.
- unused (en jaune) : c’est la mémoire qui est actuellement non utilisée par le système.
- swap (en ligne orange en bas) : représente la quantité de mémoire virtuelle utilisée. Le swap est une extension de la mémoire RAM sur le disque dur/SSD/carte SD/EMMC. L’utilisation du swap est à éviter autant que possible. Le swap est extrèmement lent, y écrire fréquemment use les supports fragiles et quand RAM et swap sont pleins, le système plante et ne redémarre pas si un watchdog n’a pas été mis en place.
- vmalloc_used (en ligne rouge en bas) : la quantité de mémoire virtuelle allouée pour le kernel.
Les valeurs en bas du graphique montrent les statistiques courantes (Cur), minimales (Min), moyennes (Avg) et maximales (Max) pour chaque catégorie sur la période représentée.
Le graphique montre une utilisation stable de la mémoire avec une légère tendance à la hausse sur la période observée, ce qui peut être normal en fonction des applications et des services s’exécutant sur le système. Le système ne semble pas saturé, car il y a encore de la mémoire « unused » (inutilisée) et la quantité de swap utilisée est faible, ce qui indique que le système n’a pas besoin de recourir excessivement à la mémoire virtuelle, ce qui ralentirait les performances.
Il est également important de noter que le graphique inclut les mémoires tampon et le cache comme de la mémoire utilisée, alors qu’en réalité, cette mémoire peut être libérée si des applications en ont besoin, ce qui est une stratégie d’optimisation courante dans les systèmes Linux.
Et pour finir, une charge CPU (load average) de 3 sur une machine dotée de 6 coeurs n’est absolument pas inquiétant. Le CPU est loin d’être saturé.
Sur un système tel l’Atalas (dotée d’un CPU à 6 cœurs), un « load average » de 3 signifie que, en moyenne, la moitié des cœurs du CPU sont utilisés. Un « load average » de 1.0 signifie que l’ensemble des cœurs est chargé à 100 % (en considérant que le CPU n’a qu’un seul cœur), donc avec un CPU à 6 cœurs, un « load average » jusqu’à 6.0 signifierait que la machine est à pleine capacité (sans compter le multithreading, si disponible et applicable).
Un « load average » de 3 n’est donc pas particulièrement inquiétant, surtout si les processus sont optimisés pour le multitâche. Cela indique que le système est utilisé, mais qu’il a encore de la capacité de traitement disponible. Pour un serveur web ou une application qui gère beaucoup de petites tâches concurrentes, un « load average » légèrement supérieur au nombre de cœurs peut ne pas être inquiétant.
Bref, en conclusion cette machine ne semble absolument pas en difficulté. Quant au titre, il est erroné. On n’est pas du tout dans le cadre d’une fuite mémoire. Une fuite mémoire, c’est ça : Wikipedia - Fuite mémoire.
Tu as optimisé tes scenarios, tu obtiens le résultat que tu souhaites, le système d’exploitation ne plante pas, Linux (le noyau) ne se met pas à tuer des programmes pour protéger l’OS, ce qui rendrait Jeedom inutilisable ? Donc tout va bien. Jette un œil de temps en temps, mais tant que tout fonctionne, tout va bien ![]()
1 « J'aime »
Quand tu mets à jour les plugins, les deamons redémarrent.
C’est peu être le signe que c’est un des ces plugins qui te posait problème.
Cf longue explication de @pommedapi …
A première vue, il n’y a pas de PB et oui, il est normal de récupérer de la ram si on redémarre les process. mais ça ne veut absolument pas dire qu’il y a un pb.
Le graphique mémoire montre une tendance asymptotique, ce qui est un fonctionnement NORMAL d’un système linux
Norbert
Merci encore une fois pour vos explications que je comprends.
Ma seule crainte c’est que Jeedom se plante (encore) et il faudra alors bien admettre que c’est bien lie aux performances…
Voici le monitoring des performances, on voit bien encore la RAM qui baisse (mais bon c’est apparement normale), la charge CPU acceptable pour une Atlas et aussi un swap qui grimpe.
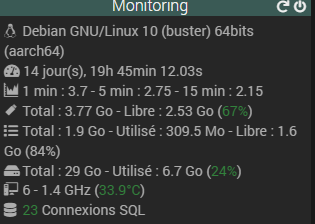
Bref, je ne touche plus et je reviens des que ca crashe.
Sebastien
Bonjour,
Et MERCI pour tes réponses très explicatives.
Je rencontre un problème qui ne semble pas être décrit dans tes réponses.
Pi4 4Go, SSD mSATA, SWAP : 2048, Jeedom 4.3.23 stable
Je ne consomme pas de RAM et je consomme du SWAP, tous les jours un peu plus. Je n’arrive pas à trouver d’explication.
Si je retourne sur Raspberry Pi OS Buster 64 bits sur la même machine, je ne consomme plus du tout de Swap et 1 Go sur la RAM en moyenne
De retour sur Raspberry Pi OS Bullseye 64 bits, la machine consomme du Swap alors que la mémoire RAM ne semble pas être sollicité (c’est ma configuration par défaut, prod).
J’ai remarqué, mais cela ne veut certainement rien dire, que si j’arrête le plugin RFXCom et ZwaveJS, cela libère instantanément du Swap.
Graphe montrant l’usage de la RAM et du Swap, pas de pic de CPU en dehors du passages des CRON.
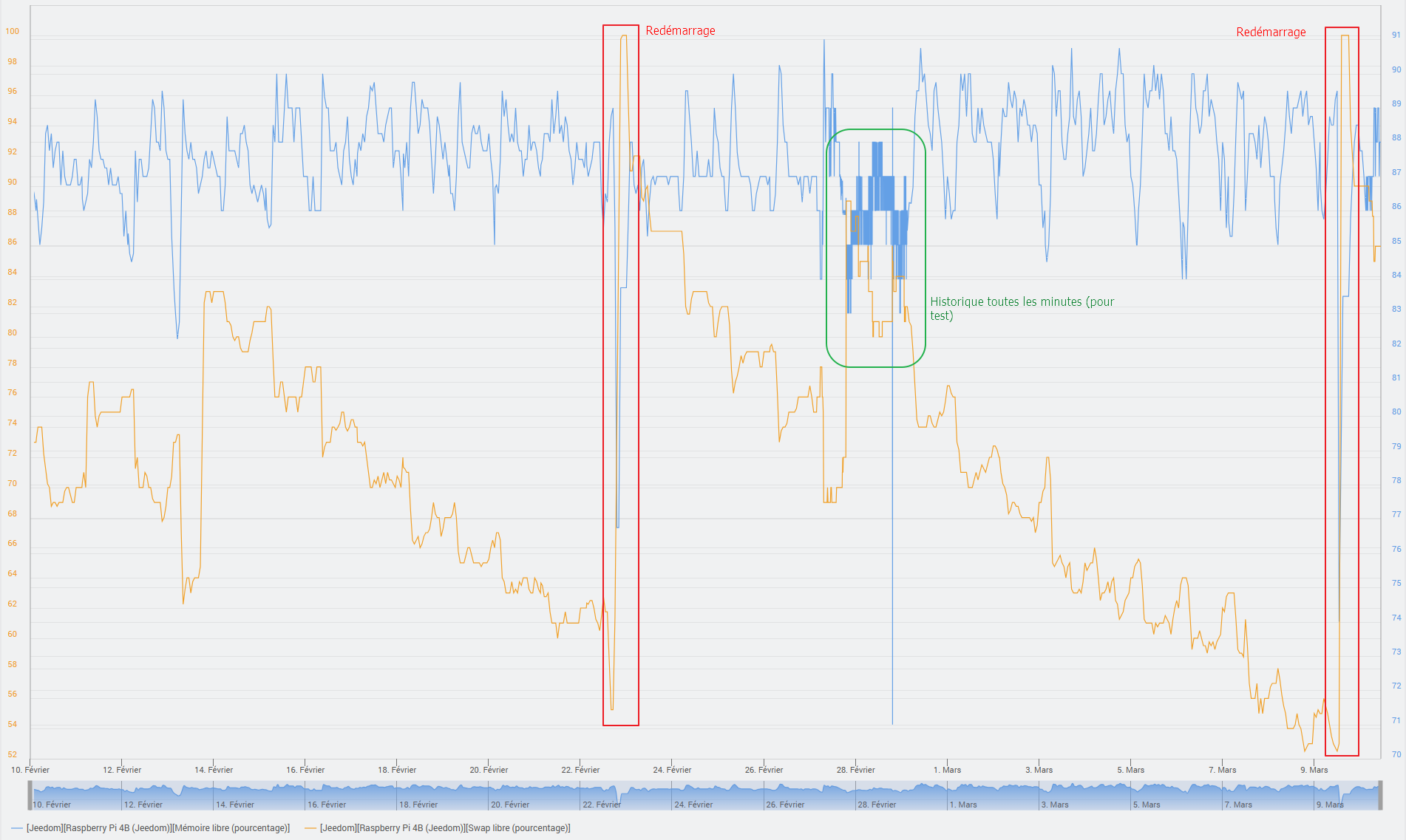
J’ai cette même sauvegarde, sur Jeedom Alpha 4.4.2, restaurée sur un Pi3B+ (1 Go de RAM) qui tourne sur Bullseye 32 bits qui ne consomme pas plus de 5 ou 10%
A la différence que cette machine n’a pas le Demon ON sur les plugins RFXCom et ZwaveJS (car je n’ai pas de dongle de test).
Je n’ai pas de scénario qui s’active tout le temps.
Ce qui m’étonne, c’est surtout le retour (que je ne veux pas) en Raspberry Pi OS Buster sur la même machine et le Swap est à 0.
Dans cette image, le reboot est trop proche, mais d’ici quelques jours, on y verra Python3, Node et MariaDB consommer du Swap
Preneur de toutes idées !
Merci
Edit :
Test que j’ai effectué :
Swapiness à 1 (c’est indiqué dans la FAQ de MariaDB) = cela swap quand même (pourtant je n’ai jamais vue la RAM passer sous les 70% en crête d’utilisation, mais rien ne prouve que cela n’est pas ce qui se passe en vraie
Désactivation du SWAP : La machine devient lente, à ne rien comprendre, même l’accès au terminal SSH est lent, la recherche des mises à jour de Jeedom aussi etc… a croire qu’il faut obligatoirement du SWAP.
1 « J'aime »
Bonjour à tous,
La gestion de la mémoire est un sujet très complexe et comprendre d’où peut venir ton problème n’est pas du tout simple.
J’avoue ne pas connaître en détails cette box officielle de Jeedom mais je suis étonné de la valeur du swapiness à 100 qui indique à l’OS de toujours privilégier le SWAP à la mémoire.
Je pense qu’il y a une subtilité qu’il faudrait étudier.
Pour ma part, je désactive systématiquement le swap sur mes VMs. Je préfère de loin détecter au plus tôt un problème d’utilisation de la mémoire (fuite mémoire, charge supérieure à ce que peut fournir le hardware, …) qu’avoir un problème de performance en utilisant du disque en place de la mémoire.
De plus, utiliser du swap indique que la mémoire disponible n’est plus en adéquation avec l’utilisation du hardware et n’est qu’une solution temporaire à un instant T.
Comme indiqué dans les échanges, il ne faut pas regarder la mémoire libre mais la mémoire disponible.
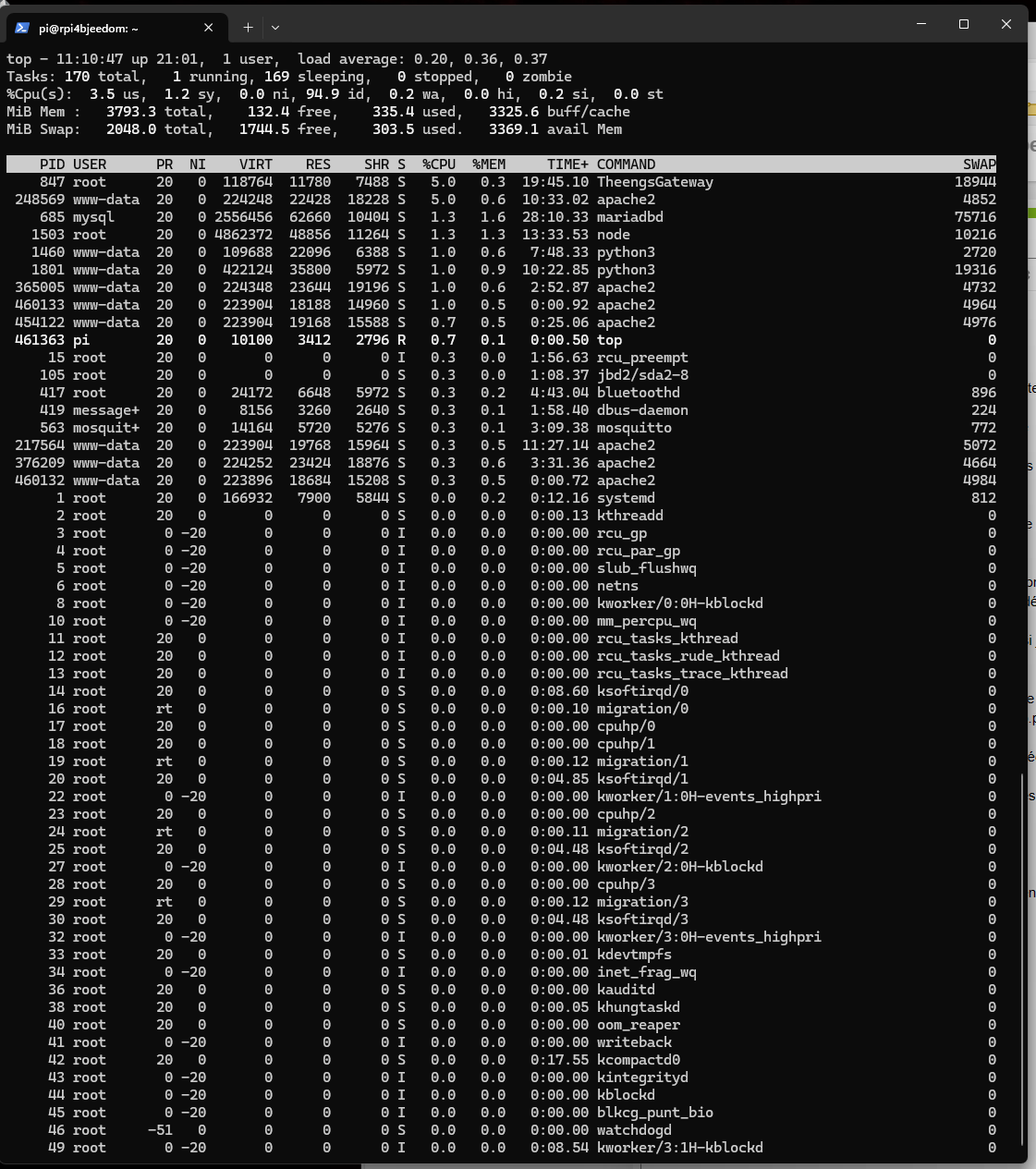
Commande « top » :

Commande « free -m » :
![]()
Sur ces 2 captures d’écran, on pourrait penser qu’il n’y a plus que 6,5Go de libre sur 16Go de mémoire libre. Il y a en fait 13,5Go de libre sur les 16Go.
Linux a alloué à un instant 7,6Go de mémoire pour diverses raisons mais ne va les libérer si et seulement si un process lui demande de la mémoire.
Il faut donc aussi faire un monitoring de cette information et non pas uniquement la mémoire libre.
Dans ton cas précis, je désactiverai le swap (est-ce recommandé ou pas sur une atlas), un reboot pour être sur de bonne base et je ferai un monitoring de la mémoire disponible (et aussi de la mémoire libre vu qu’ils sont liés) et j’attendrai que l’OS utilise un mécanisme interne (oom-killer) pour voir si tu as un vrai soucis de mémoire. L’oom-killer est un mécanisme interne à Linux qui va supprimer un process le « plus gourmand » en mémoire afin de préserver l’OS
Si il n’y a aucun soucis, bingo… sinon il faudra investiguer plus en détails et activer un à un tous tes plugins jusqu’à avoir une idée de ce qui pourrait poser problème.
A ta disposition si tu souhaites plus de détails…
[EDIT] : je viens de supprimer le paragraphe concernant la coïncidence sur la mémoire libre après lecture du code de Jeedom. Le total indiqué sur la ligne « Mémoire disponible » n’est pas le total de mémoire disponible mais le total de mémoire sur la box.
La seule indication d’une utilisation excessive de la mémoire est donc un pourcentage basé sur la mémoire disponible (et non pas uniquement la mémoire libre).
Entre les 2 dates, on passe donc de 47% à 40% de mémoire disponible avec un swap disponible de 98% à 69%
1 « J'aime »
Je t’encourage à suivre ce qu’a énoncé MasterChief. Je ferais de même.
Une réflexion supplémentaire tout de même. Si ce n’est pas un problème matériel (ce dont je doute, mais il faudra peut-être lever ce point), c’est un problème logiciel. La gestion de la RAM est du domaine de l’OS. Et donc, question, l’image ayant servie à installer la version problématique vient d’où ? Suivant les paramètres définis lors de la création de l’image, on peut avoir des réglages par défaut très différents d’une image à l’autre.
[edit] J’ai retrouvé un message que j’avais lu, mais pas sauvegardé sur le calcul de l’usage de la mémoire entre Debian 11 et 12 :
PSA: the way the “free” command calculates unused memory changed significantly between Bullseye and Bookworm
Une traduction possible serait :
« Bookworm [Debian 12] a mis à jour le paquet procps-ng, qui inclut la commande « free ». Une des choses qui a changé est que la façon dont la mémoire « inutilisée » est calculée inclut maintenant la mémoire partagée qui n’était pas comptée auparavant - rapport de bogue ici. Le résultat final est que Bookworm montrera une utilisation plus importante de la mémoire vive que Bullseye [Debian 11], même avec la même configuration. Cependant, comme le confirme l’inspection de /proc/meminfo, il n’y a pas eu de changement significatif dans l’utilisation de la mémoire vive.
Curieusement, Arch Linux utilise toujours la version obsolète de procps-ng. J’ai découvert cela en m’arrachant les cheveux en essayant de comprendre pourquoi Bullseye utilisait 85 mégaoctets de mémoire vive, alors que Bookworm en utilisait 200 mégaoctets. J’ai vérifié une installation d’Arch pour voir s’il s’agissait d’un changement dans le nouveau noyau Linux, mais Arch a indiqué 90 mégaoctets. Finalement, j’ai compris ce qui se passait, et si vous exécutez l’ancienne version de « free » sur Bookworm, elle indique 85 Mo (sur mon système ; le vôtre sera évidemment différent en fonction des modules du noyau). […] »
Attention à bien comparer des pommes avec des pommes et non des pommes et des carottes. Ce changement est particulièrement piégeux quand on n’est pas au courant.
1 « J'aime »
Bonjour à tous et toutes!
Je reviens avec mes problèmes de fuites de mémoire et je pense avoir mis la main sur la cause du problème qui est en plus à 100% de ma faute.
Je fais beaucoup de gestion d’energie (électrictité) avec Jeedom et je gère de ce fait de la production solaire …
Au depart j’utilisai des scripts PHP dans un scénario pour lire les données de mes onduleurs SMA.
Puis j’ai fait un plugin SMA_SunnyBoy qui en gros utilisait les même script PHP pour la lecture des données des onduleurs SMA. Le plugin utilisait un CRON (1 minute d’interval pour le rafraichissement des données).
Finalement j’ai rajouté un Daemon PHP afin d’augmenter la fréquence de rafraichissement / lecture des données des onduleurs.
Depuis les scripts php dans un scénario (au départs), j’avais déja des ‹ fuites › de mémoire mais je ne pouvais pas clairement identifé que la cause était ces scripts …
D’ailleurs avec le plugin sans Daemon non plus …
Mais là en ayant rajouté un Daemon PHP, je vois que la mémoire associé à ce process ID du Daemon est la cause de la fuite de mémoire et dès lors que je désactive le plugin toute la mémoire se libère. Je peux alors réactiver le plugin et c’est reparti pour un temps jusqu’à ce qu’il y ait à nouveau saturation.
Bref, c’est mon foutu plugin qui en est la cause ![]() (ahh le nul)
(ahh le nul)
Je vais de suite aller demander dans le forum des devs si quelqun peut inspecter mon plugin afin de voir où ce problème de fuite de mémoire peut être situé. J’ai essayé de trouver sans succès et je loupe forcement un truc certainement par manque de savoir/experience.
Merci,
Sébastien
2 « J'aime »
Je salue le « mea-culpa » ![]()
mais j’avoue que ca m’a fait un peu (beaucoup) sourire… « tout ça pour ça » ![]() , sans oublier qu’il n’y a que ceux qui ne font rien qui ne font pas d’erreurs
, sans oublier qu’il n’y a que ceux qui ne font rien qui ne font pas d’erreurs ![]()
2 « J'aime »